7.6. «Фамильный портрет» русского народа
|
§1. Различия и сходство регионов: В анализе 14 000 коренных фамилий - Сходство фамилий средней полосы - Своеобразие «полярных» регионов - Подтвердился анализ «топ-20» и «осмысленных» классов «топ-50»!
§2. Фамилии и маркёры Y хромосомы: Индивиды: похожи ли Y хромосомы у однофамильцев? - Популяции: фамилии и генофонд - На Русской равнине география фамилий и Y хромосомы сходна - Высокая коррекция между матрицами расстояний для «настоящих» генов и для фамилий §3. «Главные сценарии» изменчивости: Среднерусская полоса - Постепенное изменение фамилий к югу - Своеобразие Русского Севера - Корреляции «главных сценариев» фамилий, антропологии и генетики §4. География инбридинга: Как узнать инбридинг по фамилиям? - Прогноз груза наследственных болезней - Русский генофонд - Неуклонный рост инбридинга с юго-запада на восток §5. Основные черты «фамильного портрета»: «Осмысленная» классификация фамилий и регионов - Парадоксально надёжные маркёры - Фамилии не ради фамилий - Лицо генофонда - Разведка боем Как и в предыдущих главах второй части книги, заключительный раздел вбирает те виды анализа, которые абстрагируются от отдельных признаков и выявляют общие черты генофонда. Это позволяет нам забыть на время о том, какими именно признаками мы пользовались, и вглядеться, наконец, в тот общий план строения русского генофонда, который проявляется в рассматриваемом типе признаков. В. этой главе есть и уже привычные карты главных компонент - «главных сценариев» изменчивости генофонда (§.3). Однако для фамилий этот параграф не центральный. Дело в том, что карты «главных сценариев» пока предварительные - они опираются на небольшой набор фамилий (75) и лишь половина популяций надёжна («районного масштаба»). Поэтому основной акцент мы сделаем на другом виде анализа - на выявлении соотношений между основными частями генофонда по всем 14 тысячам коренных фамилий сразу. Такую оценку различия и сходства регионов (§1) мы получим с помощью обобщённых расстояний между регионами и диаграмм многомерного шкалирования - то есть так же, как в предыдущей главе для маркёров митохондриальной ДНК и Y хромосомы. Это позволит нам сравнить обобщённые расстояния, рассчитанные по фамилиям, с генетическими расстояниями между теми же регионами, рассчитанными по маркёрам Y хромосомы (§2). Такое сравнение, во-первых, интригующе интересно ведь оба типа признаков передаются по отцовской линии. А во-вторых, мы имеем редкую возможность сравнить их без карт - и фамилии, и Y хромосома изучены нами в одних и тех же русских популяциях. А вот последний вид анализа можно провести только по фамилиям. Это - прогноз инбридинга и связанного с ним груза наследственной патологии (§4). Все виды анализа вместе помогут составить обобщённый «фамильный портрет» русского генофонда. §1. Различия и сходство регионоВЕСЬ ФОНД ФАМИЛИЙ Каков портрет русского генофонда, рисуемый не оттенками двух-пяти десятков самых частых фамилий, а разноцветьем всего многотысячного спектра русских фамилий? Как по всему спектру фамилий русский генофонд подразделяется на региональные части? Каковы соотношения между региональными «фамильными фондами»? Отвечая на эти вопросы, мы можем располагать данными лишь о пяти регионах «исконного» ареала, поэтому структура генофонда выявится лишь в общих чертах. Но именно эти общие черты для нас сейчас и важны. В последующих разделах (§2 и §3) картографирование по данным о 100 популяциях поможет взглянуть на детали структуры генофонда. Чтобы оценить истинные «взаимоотношения» регионов, мы включили в анализ весь фонд «коренных» фамилий. Использованы данные по всем фамилиям - и всеобщим, и уникальным. Единственное условие - анализируемые фамилии должны быть «коренными», чтобы мятущиеся ветры миграций не создавали эфемерную видимость близости или удалённости популяций. АЛГОРИТМЫ АНАЛИЗА МЕРА СХОДСТВА. Напомним, что в предыдущих разделах этой главы для выявления сходства и различий регионов по частым фамилиям («топ-10» или «топ-50»,) мы использовали самые разные показатели, чтобы максимально сохранить «лицо» фамилий, сравнить их «поимённо». Но теперь, при обобщённом анализе всего фонда фамилий, мы воспользуемся общепринятой в популяционной генетике мерой сравнения популяций - генетических расстояний М. Nei (1975). АЛГОРИТМ РАСЧЕТА. Напомним, что в анализ включена информация о распространении 14 тысяч «коренных» фамилий. Носители этих фамилий - 725 тысяч человек из пяти основных регионов «исконного» ареала. «Пришлые», случайные и потому редкие для данного района фамилии отсеяны согласно «демографическому» критерию (раздел 7.3., §2). Частоты фамилий (см. разделы 3.2. и 7.2.) были сначала рассчитаны для каждого района. По совокупности «районных» частот рассчитаны невзвешенные частоты фамилий в регионе. По региональным частотам рассчитаны генетические расстояния между регионами. По этой матрице расстояний построен график многомерного шкалирования. КТО НА КОГО ПОХОЖ? Степень сходства пяти основных регионов друг с другом показана на рис. 7.6.1. 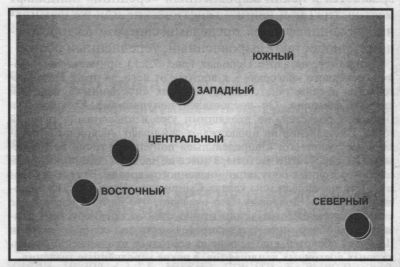
Рис. 7.6.1. Сходство и различия пяти основных регионов по всем «коренным» фамилиям (14 428 фамилий) Диаграмма многомерного шкалирования построена по обобщённым генетическим расстояниям [Nei, 1975]. СЕВЕРНЫЙ РЕГИОН (среднее расстояние от остальных регионов dN=1.1)3 оказался наиболее своеобразным. Примечательно, что он удалён от всех регионов без исключения (1.0 ЮЖНЫЙ РЕГИОН (dS=1.0) занимает второе место по своеобразию фамилий. Он также расположен на периферии «фамильного пространства» (рис. 7.6.1.). «Южные» фамилии ближе всех к «западным», но расстояние и между ними немалое (dS-W=0.7). ВОСТОЧНЫЙ РЕГИОН (dE=0.9) оказывается на третьем месте по своеобразию фамилий. Он максимально удалён от обоих «полярных регионов» (в среднем dE-POLE=1.3). Но при этом близок к другим двум регионам среднерусской полосы (в среднем dE-MIDDLE ZONE=0-5)- Из этих двух регионов он особенно близок к соседнему Центральному региону (dE-C=0.3). Так что в пределах среднерусской полосы Восточный регион не обнаруживает рассогласования с географическими расстояниями, а напротив, строго следует им. Видимо, здесь география и история были согласны друг с другом. ЗАПАДНЫЙ РЕГИОН (dE=0.7) оказывается равноудален от Южного (dW-S=0.7) и Восточного (dE=0.8) регионов, и близок к Центральному (dW-C=0.3). ЦЕНТРАЛЬНЫЙ РЕГИОН (dC=0.7) занял действительно центральное место в русском генофонде. Он почти в равной степени удалён от «полярных регионов» (dC-N=l.l; dC-S=0.9) и одинаково близок к регионам средней полосы (dC-W=0.3; dC-E=0.3). Однако, хотя кажется, что здесь географические и генетические расстояния полностью ладят друг с другом, но история вмешивается и здесь. Генетические расстояния до регионов средней полосы оказались в три-четыре раза меньше, чем до «полярных». А разница в географических расстояниях невелика - лишь в полтора раза (Центр/3апад=400 км, Центр/Восток=450 км, Центр/ Юг=600 км, Центр/Север=700 км). Таким образом, по частотам фамилий Центральный регион куда более удалён от полярных регионов, чем ожидалось из географии. ПОДВЕДЁМ ИТОГИ Итак, генетические расстояния, рассчитанные по всему фонду фамилий (14 тыс. фамилий), выделяют среднюю полосу европейской России (Западный, Центральный, Восточный регионы) как наиболее полно воспроизводящую средние характеристики русского генофонда. «Полярные» Южный и Северный регионы демонстрируют выраженное своеобразие состава фамилий. При этом Восточный регион резко отличен от «полярных» регионов; Южный тяготеет к Западному; а Северный регион занимает совершенно особое место. График на рис. 7.6.1. иллюстрирует эти взаимоотношения регионов. Не правда ли, знакомая картина? Мы её видели и тогда, когда рассматривали самые частые фамилии - «топ-20» (раздел 7.3.); и тогда, когда создавали «фамильные портреты» регионов по «топ-50» (раздел 7.4.). Такое взаимное подтверждение трёх независимых видов анализа - по частым фамилиям «топ-20», по «осмысленным» классам «топ-50» и по частотам всего массива «коренных» фамилий - радует, а уверенность в том, что мы на верном пути, растёт. Из этого следуют и методические выводы. Во-первых, это значит, что наше выделение классов фамилий (календарные, профессиональные, «звериные», «приметные») работает неплохо. Во-вторых, если даже анализ «топ-50», то есть только полусотни самых частых фамилий (и отсев всех остальных фамилий), сохраняет основные тенденции, то значит и наш отсев лишь самых редких «пришлых» фамилий вряд ли эти тенденции исказил. Но тогда возникает здравый вопрос. Может быть, и нет необходимости анализировать всю громаду всех фамилий, а заниматься только частыми? К сожалению, это не так. Прежде всего, не изучив все фамилии, не определишь, какие из них частые. Но главное, мы никогда не знаем, где та граница, после которой начинаются искажения тенденций. Ведь для разных регионов число «репрезентативных фамилий» может оказаться различным в зависимости от структурированности генофонда. Кроме того, разные группы фамилий - общие, частые, уникальные - могут описывать особые закономерности, не свойственные генофонду в целом, и сообщить много любопытных сведений об истории сложения генофонда. §2. Фамилии и маркёры Y хромосомыИтак, мы определили взаимное положение пяти основных регионов по данным о фамилиях. Но можно ли утверждать, что таково взаимное положение не только «фамильных портретов» регионов, а самих генофондов? Можно ли считать, что, изучая фамилии, мы видим генофонд? Чтобы ответить на этот вопрос, надо привлечь свидетельства ещё одного очевидца - данные самой генетики. Те же самые популяции, которые мы изучили по фамилиям, уже генотипированы нами по одной системе генетических маркёров - по маркёрам Y хромосомы. Причём именно эти маркёры наиболее интересны для сравнения с фамилиями: и те, и другие передаются по мужской линии. Так что совместное изучение русских фамилий и Y хромосомы полезно им обоим. Как известно, Y хромосома передаётся от отца к сыну, так же как и фамилия у народов с патронимической традицией. Однако связь между фамилией и гаплотипом Y хромосомы далека от абсолютной - она нарушается как «мутацией» фамилии (изменения в написании, возникновения у потомков новой фамилии), так и в случаях внебрачных детей и усыновлений, или же при передаче фамилии от матери [Sykes, Irven, 2000; Jobling, 2001]. Кроме того, в отличие от гаплотипов. фамилии возникли исторически совсем «недавно» - считается, что самые древние фамилии возникли в Китае около 5000 лет назад [Jobling, 2001]. Однако основная масса современных фамилий народов мира возникла в пределах последней тысячи лет. В результате одинаковые гаплотипы встречаются у людей с разными фамилиями, и наоборот - у людей с одинаковой фамилией встречаются разные неродственные гаплотипы. Можно выделить два основных направления, в которых ведутся работы в данной области. РАЗНООБРАЗИЕ Y ХРОМОСОМЫ У ОДНОФАМИЛЬЦЕВ Это направление рассматривает связь конкретной фамилии и конкретной Y хромосомы. В рамках этого направления в настоящий момент проводится большая часть работ по изучению связи фамилии и генотипа: фамилия выступает как квазигенетический маркёр конкретной Y хромосомы. В 2000 году Sykes и Irven исследовали гаплотипы Y хромосомы носителей фамилии первого из авторов [Sykes, Irven, 2000]. Авторы ожидали, что фамилия Sykes возникала многократно, поскольку происходит от диалектного Йоркширского «ручей», «канава». К своему удивлению, они обнаружили, что у 43,8% исследованных однофамильцев - один и тот же гаплотип Y хромосомы, причём следующий по частоте гаплотип встречается в 4 раза реже. Это позволило авторам оценить время жизни основателя гаплотипа и, что важнее для других исследователей - долю «не-отцовства» (от англ. non-paternity - частоты получения фамилии не от биологического отца, а точнее - Y хромосомы не от формального отца). Доля «не-отцовства» составила 1,3% за поколение. Оценки этой же величины у других авторов колеблются в основном от 2 до 5% [Maclntyre, Sooman, 1991]. Довольно смелые выводы делает другой автор [King et al., 2006]. С большим количеством оговорок и в предположении создания в будущем (но пока лишь «умозрительной») базы данных о соответствующих друг другу гаплотипах Y хромосомы и фамилиях. он предлагает ДНК тестирование для определения возможной фамилии преступника, «оставившего ДНК» на месте преступления. Автор предлагает использовать такой подход в качестве дополнительных (хотя и не веских самих по себе) улик и сужения круга подозреваемых. Для того чтобы предлагать такой метод, автор исследует корреляцию гаплотипов в парах однофамильцев в Англии и показывает, что эта корреляция наличествует, хотя и не очень высока. Он показывает на конкретных данных, что лица с редкими фамилиями чаще оказываются родственниками по отцовской линии, чем лица с частыми фамилиями. Иногда мотивом для исследования однофамильцев является «проверка мифа» - попытка найти следы древнего героического предка у потомков фамилий, по легендам происходящих из его колена. Такова, например, работа Moore с соавторами [Moore et al., 2006]. в которой исследуются ирландцы - народ, видимо, начавший использовать фамилии раньше других современных европейских народов. Хотя работа в целом носит популяционный характер (сперва исследуются случайные выборки из разных частей Ирландии). в ней исследуются представители фамилий, по легендам происходящих от династии Uí Néill (буквально потомки Найала). Оказалось, что 52.5% изученной выборки принадлежат одному гаплотипу, который произошёл около 1730 (±670) лет назад. Неизвестно. как звали человека, основавшего эту линию, но он имеет непосредственное отношение к происхождению потомков Найала. Потомки этого колена, видимо, обладали социально определяемой повышенной приспособленностью (способностью оставлять большее количество потомков), а именно - родовитостью (которая определяется фамилией), и их прирост в каждом поколении с 500 года н.э. составил =21% за поколение. В аналогичной по задачам работе, «когда мы понимаем мифы о населении буквально» [Jobling. 2001], авторы проверяли легенду о происхождении всего корейского народа от одного относительно недавнего легендарного предка по имени Tangoon и, как можно было ожидать, получили отрицательный результат. К этому же разделу «пофамильных исследований» относятся и другие работы - например, McEvoy и Bradley [2006]. Авторы исследуют различия разнообразия гаплотипов у однофамильцев в зависимости от того, как часто фамилии «мутировали» - возникали новые фамилии из старых. В Ирландии одной из причин параллельного возникновения фамилий была англицизация ирландских фамилий. Например, фамилии Mac Fhíodhbhuidhe и Mac an Bheatha, которые не перепутал бы ни один ирландец, англичане записали одинаково - McEvoy, и у носителей этой фамилии чётко выделяется два основателя, время жизни которых отличается более чем на 500 лет. Подводя итог этого направления исследований, можно сказать, что они показали, каков приток «в фамилию» генов из других фамилий (первая работа такого рода осуществлена в 1973 году [Genest, 1973], но основной ряд работ выполнен только в последние пять лет) и какова непосредственная связь между фамилией и гаплотипом Y хромосомы. «Пофамильное» направление представляет большой интерес и для частных лиц, интересующихся своей родословной. Можно только порадоваться за знаменитого профессора Bryan Sykes и за Brian McEvoy, которые смогли совместить интереснейшую для науки работу с удовлетворением собственного любопытства по поводу происхождения своей фамилии. ПОПУЛЯЦИОННАЯ СВЯЗЬ ФАМИЛИИ И ГЕНОТИПА Это второе направление исследований, изучающих сопряженность фамилии и Y хромосомы. Оно нацелено на анализ генетических различий между популяциями, различающихся по происхождению фамилий. Здесь фамилия выступает не как квазигенетический маркёр конкретной Y хромосомы, а как квазигенетический маркёр популяции. В этом случае оказывается не важно, насколько велика связь конкретной фамилии с конкретной Y хромосомой: фамилия как признак культуры становится в один ряд с другими квазигенетическими маркёрами или характеристиками популяции - лингвистическими, этнографическими и прочими. Также как, например, наличие определённого узора на традиционной одежде или же наличие сходных мотивов в мифах, так и сходство популяций по большому числу фамилий может указывать на возможную близость популяций. При популяционном подходе отдельные случаи «не-отцовства» не отражаются на популяционных частотах фамилий, поскольку эти случаи редки и в целом компенсируют друг друга. Во всех работах подчёркивается, что огромным преимуществом фамилий по сравнению с другими квазигенетическими маркёрами является возможность тотального исследования населения. В работе Zei и соавторов [Zei et al., 2003] исследуется население Сардинии. Выборка подразделяется по месту происхождения коренных сардинских фамилий, которое определяется по области Сардинии с максимальными частотами данной фамилии, а также по историческим источникам. Фамилии отнесены к трём историко-географическим зонам Сардинии. Показаны генетические различия между популяциями, фамилии которых принадлежат разным регионам. В работе Immel и соавторов [Immel et al., 2006] две сравниваемые группы формируются из одной выборки - жителей г. Галле (Германия). Выборка разделена по происхождению фамилий обследуемых: у 195 мужчин фамилии немецкого (группа G); у 185 фамилии славянского происхождения (группа S); у 39 человек фамилии смешанного происхождения (группа М). В качестве сравниваемых групп использовались данные о 29 сорбах (коренное славянское этническое меньшинство, проживающее на границе с Польшей) и о 1313 поляках из [Roewer et al., 2005]. Была показана генетическая близость группы (S) с поляками и сорбами и значительно большее генетическое расстояние от этих трёх групп до смешанной группы, включающей генетически не различающиеся выборки (G) и (М). Наиболее любопытной нам кажется работа Bedoya с соавторами [Bedoya et al., 2006], поскольку она сочетает в себе подходы популяционных и «пофамильных» исследований. В работе привлекаются данные о динамике частот фамилий за несколько последних веков, чтобы определить характер изменения популяционной структуры в этот период. Работа посвящена горному изоляту в Колумбии, основным фактором популяционной динамики которого была иммиграция испанцев, действовавшая с той или иной интенсивностью после их первого появления на территории Колумбии. Сходство распределений фамилий в конце XVIII века и в наше время при возрастании с тех пор численности населения в 107 раз позволяет авторам утверждать, что, по крайней мере, с конца XVIII века основным фактором динамики популяций был её рост, а не иммиграция из Европы. Этот вывод чрезвычайно важен для интерпретации результатов молекулярно-генетического анализа, проводимого авторами, и уточнения времени формирования наблюдаемых особенностей популяционного генофонда. Аналогичная работа была проведена ранее нами [Почешхова, 1998; Балановская и др.. 1999; Балановская и др., 2000] по изучению фамилий древнейшего коренного населения Западного Кавказа - адыгейцев и шапсугов. В работе, охватывающей тотально всех шапсугов, прослежена динамика их фамилий (населявших ранее побережье Черного моря от Туапсе до Сочи) на протяжении шести поколений. Такое глубокое знание генеалогии позволило сделать шесть «временных срезов» фамильного состава популяций, то есть реконструировать генофонд населения на одно, два, три, четыре, пять и шесть поколений назад. В результате такой реконструкции показана высочайшая устойчивость популяции: благодаря сохранению брачных традиций, она сохранила популяционную структуру вопреки переселениям и катастрофическому сокращению численности популяции в результате Кавказской войны (середина XIX века). Удивительное сходство всех шести карт главных компонент фамилий, построенных по данным о шести поколениях, и даёт нам право говорить о преемственности генофонда во времени, о сохранении его структуры даже после такой демографической катастрофы, которую претерпели шапсуги. Это означает, что с помощью фамилий мы можем проникать вглубь поколений, реконструировать генофонды прошедших времен. КОРРЕЛЯЦИЯ РУССКИХ ФАМИЛИЙ И ГАПЛОГРУПП Y ХРОМОСОМЫ Рассмотрев вкратце, каковы мировые данные о связи фамилий и Y хромосомы, обратимся к изучению этой связи в русском генофонде. Конечно, мы понимаем, что даже если мы проведём (как в случае наших русских регионов) полностью параллельный анализ одних и тех же популяций и по фамилиям, и по Y хромосоме, то всё равно полного совпадения результатов быть не может. Маркёры Y хромосомы - это «настоящие» гены, но у них есть свой изъян: по ним изучено много меньшее число популяций и человек. По Y хромосоме 1257 человек представляют 14 районов. По фамилиям изучен миллион человек из 50 районов. Разница существенная. Но у фамилий, к сожалению, есть свой и куда более важный недостаток - они только «квазигены», столь переменчивые и столь юные по сравнению с настоящими генами. Поэтому нельзя ожидать полного сходства. Но есть ли оно вообще? Те, кто заглядывал в 6 главу, уже знают, что сходство налицо. Напомним, что на карте главного сценария всех гаплогрупп Y хромосомы, мы видели чётко выраженный широтный градиент {рис. 6.3.11). Это означает, что, двигаясь с севера на юг, мы обнаруживаем намного большие различия между русскими популяциями, чем двигаясь с запада на восток. Мы видим на этой «главной» карте Y хромосомы и резкие различия Северного и Южного регионов, и сходство регионов средней полосы. Это значит, что по маркёрам Y хромосомы в главе 6 мы видели ту же картину структуры русского генофонда, которую только что прогнозировали по фамилиям. Гены и фамилии в этой общей картине русского генофонда согласны друг с другом. Но можно возразить, что это сходство отражает лишь самые общие черты генофонда, и получено оно с помощью качественных, а не количественных сравнений. Хотя мы считаем, что совпадение общих черт генофонда намного важнее количественного анализа, но проведём и его. Причём максимально строго. Выше мы рассчитали матрицу неевских генетических расстояний между пятью русскими регионами по данным о фамилиях. Проведём полностью аналогичный расчёт расстояний и для маркёров Y хромосомы. И построим матрицу тех же неевских генетических расстояний между теми же пятью основными регионами, но теперь уже по данным об изменчивости Y хромосомы. Чтобы анализ был полностью количественным, мы будем сравнивать друг с другом не диаграммы многомерного шкалирования, являющиеся «картинками», иллюстрациями этих расстояний, а сами матрицы расстояний. Коэффициент связи оценивает, насколько фамилии и гены дают похожие оценки близости между регионами, то есть оценки структуры русского генофонда. Если сходство велико, то коэффициент корреляции будет большим (при полной идентичности равен 1). Если сходства нет, то коэффициент корреляции будет равен 0. Оказалось, что коэффициент корреляции между матрицей расстояний по фамилиям и матрицей расстояний по генам очень высок и достигает 0.6. Напомним, что при введении фамилий в популяционно-генетические исследования, был проведён аналогичный анализ связи между распределением фамилий и классических маркеров. Этот анализ был проведён А. А. Ревазовым для северных русских популяций. Коэффициент корреляции оказался равным r=0.32 [Ревазов и др.. 1986]. Этого уровня связи оказалось достаточным, чтобы фамилиям присвоить почетное звание «квазигенетических маркёров» и рекомендовать использовать фамилии, как аналоги генов при изучении генофондов [Ревазов и др., 1986]. Итак, корреляция между настоящими генами и фамилиями оказалась очень велика - 0.6. Это означает сходство между структурой русского генофонда, выявляемой через фамилии и через «настоящие» гены. Оба очевидца - фамилии и генетика - дают сходные показания. Такое прямое сравнение фамилий с генетикой ещё раз показывает, какими парадоксально надежными маркёрами являются фамилии. §3. «Главные сценарии» изменчивостиРассмотренные нами «простые» карты отдельных фамилий отмечают отдельные события. Чтобы увидеть цепь этих событий, сплетающихся в единую историю русского генофонда, надо «сплавить» воедино изменчивость множества популяций и фамилий. Такое обобщение могут дать синтетические карты, созданные на основе множества карт отдельных фамилий. Для этой цели, как и по всем другим признакам - антропологии и генетики (главы 4, 5, 6) - мы провели анализ главных компонент. Геногеографические карты главных компонент являются картами новых обобщённых признаков. Они описывают основную часть разнообразия всех фамилий и выявляют основные «сценарии» их изменчивости. Однако специально проведённые разные виды анализа показали, что в составе 75 фамилий Атласа в большей степени представлены фамилии Западного и Центрального регионов и в целом - регионов среднерусской полосы, а Южный и Северный регионы отодвинуты на задний план. Это, конечно же, снижает возможности картографического Атласа фамилий в реконструкции структуры всего русского генофонда - его ландшафт мы видим с точки зрения Запада и Центра. Поэтому из-за ограниченности объёма книги мы не приводим карты главных компонент (они будут приведены на сайте). Когда же мы соберём данные, настолько полно покрывающие «исконный» ареал русского народа, что мы сможем отказаться от заданного нам списка 75 фамилий и перейти к анализу сотен и тысяч фамилий, тогда будет проведён картографический анализ «фамильного генофонда», где смещение в сторону любого из регионов будет исключено. Здесь укажем лишь, что в целом оба главных сценария фамильного ландшафта выделяют, прежде всего, среднерусскую полосу - она служит основным структурообразующим элементом обеих карт. Обе карты главных компонент имеют ещё две общие черты: постепенное изменение значений к югу ареала, и выраженное своеобразие северных русских популяций. Подчеркнём, что этот результат, полученный при картографическом анализе 100 популяций(по 75 фамилиям), подтверждает результат, полученный статистическими методами при анализе 5 регионов (но по всему фонду фамилий - более 14 тыс.). Сравним также показания фамилий и других очевидцев структуры генофонда. Такой «мультиокулярный» подход позволяет оценить, насколько карты «главных сценариев» по фамилиям сходны с теми, что обнаружила антропология и генетика. КОРРЕЛЯЦИИ МЕЖДУ «ГЛАВНЫМИ СЦЕНАРИЯМИ» ВСЕХ ПРИЗНАКОВ В нашем случае мы имеем редкую возможность сравнить показания фамилий с показаниями ещё четырёх свидетелей - соматологии, дерматоглифики, классических и ДНК маркёров. Корреляции между картами всех трёх главных компонент фамилий и остальных четырёх очевидцев приведены в таблице 7.6.1. Мы видим, что карта первой главной компоненты изменчивости фамилий (1PCF ) обнаруживает хорошее сходство с картой первой компоненты по признакам антропологии - коэффициент корреляции выше 0.6 (р=0.66). Несколько слабее связь с классическими маркёрами (р=0.44). Невысокая связь наблюдается с главным сценарием Y хромосомы (р=0.29). Однако с ландшафтом третьей компоненты Y хромосомы связь выражена чётко (р=0.49). Зато вторая компонента по фамилиям (2PCF) высоко коррелирует с обеими вторыми компонентами маркёров генетики: и по ДНК маркёрам Y хромосомы (р=0.63), и по классическим маркёрам (р=0.65) коэффициенты связи выше отметки 0.6. Также явно выражена (р=0.47) и связь карты второй компоненты изменчивости фамилий (2PCF) со второй компонентой признаков антропологии (2PCA). Важно подчеркнуть, что фамильный ландшафт второй компоненты (2PCF) обнаруживает ровный ряд корреляций с первыми компонентами всех четырёх типов признаков (связь с 1PCA, 1PCD, 1PCG, 1PCY лежит в интервале 0.23<р<0.40), указывая на связь с широтно бегущими волнами русского генофонда. В целом мы видим, что фамильный ландшафт обнаруживает связь то с одним, то с другим из иных типов признаков. Можно надеяться, что когда у нас появится возможность включить в Атлас фамилий карты не 75, а сотен и тысяч русских фамилий, то эти распавшиеся куски единой картины воссоединятся. 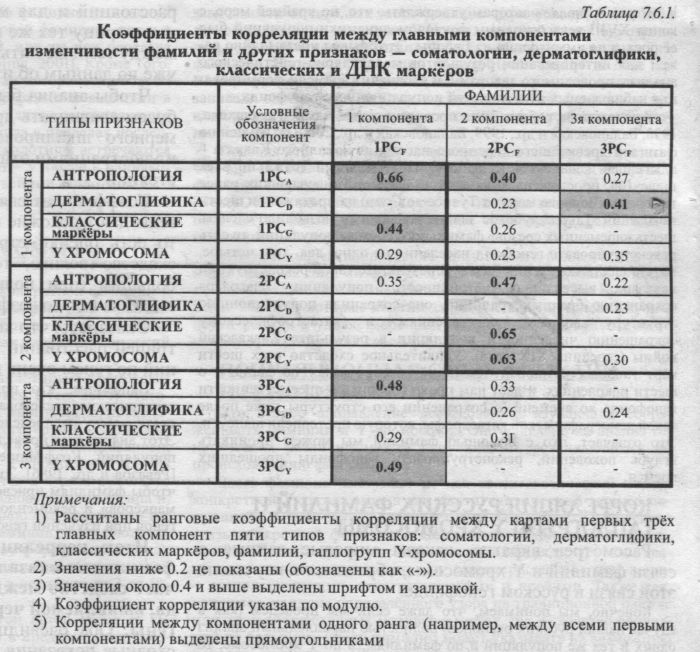
СРАВНЕНИЕ КАРТ «ГЛАВНЫХ СЦЕНАРИЕВ» ВСЕХ ПРИЗНАКОВ Напомним читателю, что корреляции, которые мы только что рассмотрели, рассчитывались вовсе не по всему «исконному» русскому ареалу, представленному на картах «главных сценариев» фамилий. К сожалению, для расчёта корреляций по всем пяти типам признаков надо использовать средний по всем признакам «надёжный» ареал, а его размер и контуры задаются теми признаками, которые наименее подробно изучены. Поэтому и «надёжный» ареал карты, по которому рассчитывались корреляции, сократился, как шагреневая кожа, до ареала наименее изученных классических маркёров (глава 5). По этой причине, может быть, важнее сравнить сами образы карт, которые позволяют составить более полное представление о сходстве и различиях «главных сценариев», чем скупые цифры корреляций. Такое сравнение обобщённых карт показывает, что первые компоненты всех четырёх типов признаков антропологии и генетики характеризуются одним и тем же - широтным - направлением изменчивости. Все четыре ландшафта различаются лишь двумя элементами: 1) положением южных «возвышенностей»; 2) степенью выраженности северного «поморского» ядра, которое фамилии выявляют особенно ярко. К этой серии карт в определённой степени близки оба фамильных ландшафта - первой и второй главных компонент изменчивости фамилий. Они как бы поделили единый ландшафт на две карты: карта первой компоненты «прозападная», а второй компоненты - «провосточная». Но обе компоненты изменчивости фамилий вместе образуют «нагорье» в области среднерусских регионов и широкие «долины» на юге и на севере. Такое деление ландшафта на две части может быть связано с несовершенством набора 75 фамилий. Возможно, что фамилии, кроме общих трендов, могут выявлять и иные закономерности, к которым менее чувствительны признаки антропологии и генетики (подобное явление для признаков дерматоглифики в Восточной Европе будет рассмотрено в следующей главе). §4. География инбридингаИтак, мы рассмотрели основные ландшафты в географии русских фамилий - карты главных компонент. Однако в геногеографии есть и другие типы обобщённых карт, которые позволяют выявить особые аспекты структуры генофонда. И среди них - карты случайного инбридинга (подразделённости популяций, степень изолированности - и, следовательно, инбредности локальных подразделений). Эти карты показывают нам структуру генофонда с новой стороны. Мы можем увидеть, какова степень подразделённости популяций в разных частях «исконного» русского ареала. Одновременно эта карта позволяет оценить вероятный груз наследственной патологии. Актуальность карт прогноза распространённости наследственных заболеваний, как и социальное значение такого прогноза, не требуют доказательств. ЧТО ТАКОЕ СЛУЧАЙНЫЙ ИНБРИДИНГ? Карта случайного инбридинга является частным случаем карт разнообразия. Она показывает, как в разных частях ареала меняется уровень случайного инбридинга. Инбридинг, и в особенности его случайная составляющая - это одно из центральных понятий в популяционной генетике, у него много разных сторон (см. Приложение). Сейчас для нас важно, что этот показатель измеряет степень подразделённости популяции. Он как бы показывает степень изолированности популяций на тех или иных территориях. Одновременно он показывает уровень изогаметации - вероятность увеличения доли гомозиготности (и, соответственно, уменьшения гетерозиготности) за счёт эффекта подразделённости популяции. Эта вероятность означает переход рецессивных генов в гомозиготное состояние и потому имеет решающее значение в формировании груза наследственной патологии — только встречаясь в гомозиготе, эти гены проявляют себя в виде тяжелейших наследственных болезней. Поэтому именно от уровня случайного инбридинга и зависит, много ли в популяции будет больных наследственной патологией. Случайный инбридинг можно рассчитать разными методами. Расчёт по данным о частотах фамилий является одним из наиболее распространённых и надёжных методов. Мы не будем подробно здесь излагать анализ инбридинга по фамилиям - он описан во множестве специальных публикаций в генетической литературе, и мы также посвятили разработке его методологии специальную работу [Балановская и др., 2000]. Инбридинг рассчитывается при анализе всей совокупности частот фамилий методом изонимии - через вероятность заключения браков между носителями одинаковых фамилий. Для одной фамилии (i). встреченной с частотой р(, коэффициент изонимии составит f= (р,:)/4. Но для популяции инбридинг оценивается по всем фамилиям сразу fr= Х(р,3)/4. Если популяция подразделенная и насчитывает несколько уровней иерархии, то для оценки f, на каждом более высоком уровне (например, региона) из её оценки надо вычесть инбридинг нижестоящих уровней (например, области, района, локальной популяции). Укажем лишь, что использование фамилий - наряду с прогнозом по классическим и молекулярным генным маркёрам - является в медицинской генетике испытанным методом прогнозирования инбридинга и связанного с ним груза наследственных болезней. Целым рядом работ двух школ - акад. РАМН Е. К. Гинтера и проф. Ю. Г. Рычкова - показано, что этот широко используемый в мировой практике метод и в населении России даёт хорошее согласие с оценками инбридинга, полученными прямым путем (см. Приложение). В частности, была составлена уникальная сводка данных по распространению наследственной патологии в населении Архангельской, Костромской, Кировской, Ростовской, Тверской областей, Краснодарского края и ряда других регионов Урала, Кавказа и Средней Азии. Анализ этих данных, собранных в ходе многолетних исследований отечественной школы медицинской генетики (возглавляемой акад. РАМН Е. К. Гинтером), сопровождался сбором демографической информации о миграциях и данных о распространении фамилий. Результаты сравнительного анализа таких данных (подробно изложенные, например, в монографии «Наследственные болезни в популяциях человека», 2002), убедительно свидетельствуют о хорошем согласии между прогнозом инбридинга по данным о фамилиях и реально наблюдаемым грузом наследственной патологии. ОЦЕНКИ ИНБРИДИНГА ДЛЯ РУССКОГО ГЕНОФОНДА Для оценок инбридинга мы использовали только информацию о популяциях пяти основных регионов «исконного» русского ареала (Восточный, Центральный, Западный, Северный, Южный). Коэффициент случайного инбридинга был рассчитан нами для каждой популяции на каждом уровне популяционной иерархии: 1) для 883 локальных популяций (fPOP); 2) для 50 районов (fDISDIS); 3) для 5 регионов (fREG); 4) для русского народа в целом (fETN>). Коэффициент инбридинга fr102, полученный по данным обо всех встреченных фамилиях в пределах русского народа, составил fP0P-ETN=0.71. Выявлено, что уровень инбридинга fr значительно варьирует среди популяций каждого уровня. Различия в уровне инбридинга отдельных районов достигают размаха двух порядков величины: 0.01 Карты инбридинга построены для каждого уровня популяционной системы русского генофонда - локальных популяций, районов, регионов. Их анализ, как и анализ большой совокупности статистических показателей, являются предметом специального анализа прогнозируемого груза наследственной патологии русского генофонда, что выходит далеко за пределы данной книги. Поэтому приведём лишь одну, но наиболее надёжную карту (рис. 7.6.2.) - инбридинга на уровне районов fDIS Карта выявляет очень ярко и чётко выраженную закономерность - неуклонное возрастание с юго-запада на восток прогнозируемого уровня случайного инбридинга и, соответственно, груза наследственной патологии. Эта карта (в совокупности с картами других показателей инбридинга fPOP, fPOP-DIS>, fDIS-REG, fPOP-REG) позволяет прогнозировать в пределах «исконного» русского ареала отягощённость русского генофонда наследственной патологией. Таким образом, данные о парадоксально надёжном маркёре - русских фамилиях - служат не только изучению истории русского генофонда, но и прогнозу груза наследственных болезней. 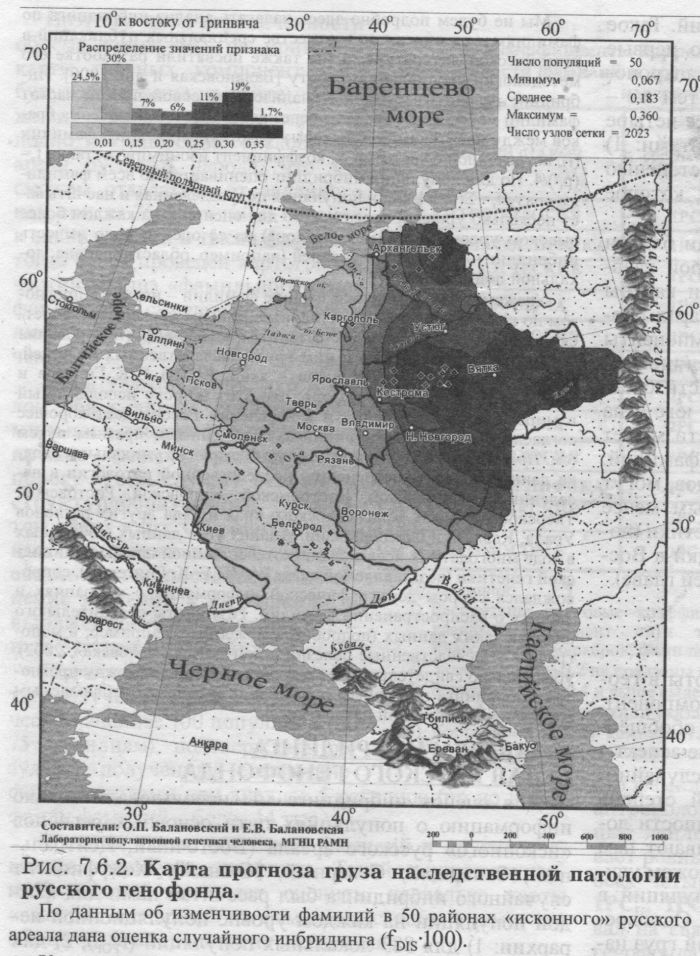
§5. Основные черты «фамильного портрета»Главой о русских фамилиях мы завершаем наше описание русского генофонда. В трёх предыдущих главах этой части книги мы анализировали данные антропологии, классические генетические и ДНК маркёры, и, наконец, в этой главе рассмотрели фамилии. Этот тип данных самый своеобразный, и его применение к изучению генофонда меньше всего разработано. Поэтому «фамильная» глава ещё больше, чем все предшествующие главы, похожа на самостоятельную книгу: в ней описываются общие принципы и подходы такого исследования, его методология, методы, история аналогичных исследований, большое внимание уделено материалам. И, разумеется, подробно описаны результаты - а их много. И получены эти результаты разными методами, несколько из которых разработаны впервые. Не удивительно, что глава о фамилиях получилась столь объемной, что её нелегко прочесть за один присест. Авторы особенно беспокоятся за ясность для читателя самой структуры исследования. Ведь применены разные методы, которые нередко давали одинаковые результаты. Не вызовет ли это путаницы, не покажутся ли разные методы повтором одного и того же из-за сходства результатов? И наоборот, не будут ли одни и те же положения выглядеть разными оттого, что к ним мы возвращаемся в разных местах главы? Структуру исследования мы постарались чётко прописать в названиях разделов - обоснование подходов и методов (7.7.), описание материалов (7.2.), общий обзор фамилий (7.3.), сравнение регионов по спектру фамилий (7.4), карты отдельных фамилий (7.5.), обобщённый анализ по всем фамилиям (7.6.). Но достаточно ли этого, чтобы поделиться с читателем той чёткостью и логикой исследования, а вместе и важнейшими результатами, которые сами авторы видят столь ясно? Чтобы приблизиться к этому, повторим некоторые положения и итоги этой главы. Это не заключение в строгом смысле - читатель не найдет здесь таких обобщений или новых мыслей, которые отсутствовали бы в предшествующих разделах. Это скорее очень краткое повторение отдельных фрагментов, которые выделяют главные линии исследования. Итак, что мы изучили и что это даёт? ФАМИЛИИ - ГЕНЫ Фамилии - привычный инструмент для популяционной генетики. Как зарубежные, так и отечественные генетики охотно использовали их для изучения структуры генофонда, в том числе для прогноза инбридинга. Недавно интерес к фамилиям усилился - благодаря сопряженности фамилий и Υ хромосомы, которые должны наследоваться параллельно по отцовской линии и, действительно, нередко ведут себя согласованно. Фамилии широко изучались и у нас в стране. Научная школа Ю. Г. Рычкова преимущественно сравнивала дифференциацию генофонда, рассчитанную по фамилиям и по генам, и всегда обнаруживала совпадения. А научная школа Е. К. Гинтера применяла фамилии чаще всего для оценки инбридинга, и в том числе А. А. Ревазову мы обязаны термином «квазигенетические» маркёры - фамилии как «почти гены». Если считать, что фамилия наследуется от отца к сыну и далее в поколениях (что в большинстве случаев совершенно справедливо!), и если знать частоты фамилий в популяциях (а собрать такие сведения вполне реально), то частоты фамилий можно рассматривать как частоты аллелей, и применить к фамилиям все обычные методы популяционной генетики. МАТЕРИАЛЫ Именно таким образом было изучено много народов, в том числе и русские популяции. Наше исследование продолжает ту же традицию, но - если позволено так сказать - на огромном материале, организованном по-новому и проанализированном целым арсеналом новых методов. Мы теперь знаем о русских фамилиях столько, сколько раньше и не надеялись узнать. Материал представляет собой частоты фамилий, которые основываются на тотально изученном населении (практически каждый житель!) пяти основных регионов. Для хранения и обработки этого огромного массива данных разработана специальная база данных о русских фамилиях, программа «ONOMA» и ряд других программ. А в сборе информации о фамилиях авторам по их просьбе помогали их коллеги Н. Н. Аболмасов, И. В. Евсеева, М. Б. Лавряшина, Э. А. Почешхова, И. Н. Сорокина, М. И. Чурносов и многие другие. Преувеличивая, можно было бы сказать, что учтена фамилия каждого русского человека - если бы не два ограничения. Во-первых, мы изучаем коренное население - это общий принцип изучения генофонда. Применительно к фамилиям это значит, что изучаем только сельское население и только в пределах «исконного» русского ареала. Центральная Россия и Русский Север изучаются, а Урал, Сибирь, Аляска и прочие «не исконные» русские территории - нет. Второе ограничение в том, что даже «исконный» ареал мы пока не изучили полностью, а выбрали семь областей из двух десятков областей исторического ареала. Эти семь областей группируются в пять регионов: Северный (Архангельская область), Восточный (Костромская область), Центральный (Кашинский район Тверской области), Западный (Смоленская область) и Южный (Белгородская, Курская и Воронежская области). В областях, как правило, изучено по несколько районов, а эти районы уже изучены тотально - собраны данные обо всём сельском населении этих районов. В дополнение к этим пяти основным регионам мы изучили три «окраинных» региона - Северо-Западный (Псковская область), кубанские казаки (Адыгея) и «Сибирь», представленную Кемеровской областью. Эти два ограничения делают наше исследование не «тотальным» (чтобы так сказать, нужно изучить фамилии каждого из 116 миллионов русских), а субтотальным - изучен «всего лишь» один миллион человек. Но этот миллион дорогого стоит - он представляет сельское население географически отдалённых друг от друга в среднем на 1000 км важнейших регионов «исконного» исторического ареала русского народа. Поэтому мы считаем, что эти данные весьма хорошо представляют русский генофонд. Для выявления основных, базовых закономерностей русских фамилий этих данных оказалось достаточно. Но по мере углубления в специальные вопросы, особенно в географию фамилий и в подробное изучение географической структуры генофонда, растёт нужда в пополнении исходной информации - необходимо собрать данные о частотах фамилий в остальных областях «исконного» русского ареала, а возможно, и за его пределами. Авторы надеются, что эти данные будут со временем собраны, а пока предлагают ознакомиться с общими, базовыми результатами, извлечёнными из уже собранного огромного массива материалов. БАЗОВЫЕ РЕЗУЛЬТАТЫ 1) Составлен список всех встретившихся фамилий, которых оказалось 67 тысяч. По мере сбора новых данных этот список будет расти, но уже сейчас, изучив восемь контрастных регионов, мы знаем основное разнообразие русских фамилий. 2) Бросается в глаза, насколько эти фамилии различаются по частоте. Одни настолько часты, что в среднем каждый сотый житель русского ареала - Кузнецов, каждый семьдесят пятый - Иванов, а почти каждый пятидесятый - Смирнов. Другие фамилии столь редки, что в том районе, где обнаружена фамилия, а порой и во всём русском ареале есть лишь считанные её носители. 3) Для многих фамилий мы построили карты их распространения. На картах видно, что почти каждой русской фамилии свойственно иметь свою географическую зону распространения, а не покрывать причудливой мозаикой русский ареал. Например, Петровы чаще всего встречаются на севере и западе, а для прочих территорий эта фамилия редкая. Такие зоны распространения могут быть удивительно компактны, а могут занимать обширные области. Для многих фамилий зоны очерчены чётко. Но для некоторых зоны прерывистые, неясные, и встречены даже фамилии распространённые то здесь, то там без всякой видимой закономерности. Правда, как раз они являются исключением, подтверждающим общее обнаруженное правило: русским фамилиям свойственно иметь определённые зоны распространения. 4) И спектр встреченных фамилий, и их частоты различаются от региона к региону. Оказалось, что все регионы средней полосы (Западный, Центральный и Восточный) похожи друг на друга. Южный регион заметно от них отличается. Но особенно своеобразен Северный регион. А вот Сибирский регион, хотя географически он самый отдалённый, по частотам фамилий очень близок к регионам средней полосы. Более того, Сибирский регион ближе всех к усреднённым русским показателям. Этот парадокс объясняется просто - Сибирь не является частью «исконного» ареала, её население - это переселенцы из «исконного» ареала, причём из самых разных его частей. Именно «плавильный котел», в котором смешались выходцы из самых разных частей «исконного» ареала, и произвёл «среднерусский» сплав: присутствие в Сибири самых разных фамилий с частотами, близкими к среднерусским частотам этих фамилий. 5) «Осмысленные классы» создают «осмысленный» портрет региона. Результаты сравнения регионов по частотам фамилий совпали с независимым сравнением регионов по семантическим классам фамилий. «ОСМЫСЛЕННАЯ» КЛАССИФИКАЦИЯ ФАМИЛИЙ Классифицирование фамилий - совсем новый подход в генетике. Обычно популяционно-генетические работы рассматривают все фамилии как равноправные признаки, неразличимые, одинаковые, безликие. И мы, сравнивая регионы по частотам фамилий, поступили точно так же. Такой статистический подход позволяет рассчитать все показатели, которые мы рассчитываем по генам. Но мы предложили дополнить его иным, новым подходом, который назвали семантическим. Его суть очень проста: надо вглядеться в лицо каждой фамилии, и отнести её к одному из классов. Например, при статистическом подходе фамилии Иванов, Петров, Никитин, Волков, Зайцев и Курочкин для нас совершенно равноправны. А при семантическом подходе Ивановых, Петровых и Никитиных мы отнесем к фамилиям, производным от имён, а Волковых, Зайцевых и Курочкиных - к фамилиям, образованным от зверей. И будем анализировать их раздельно. Важным показателем тогда станет соотношение разных классов в спектре фамилий. В нашем примере оказалось три фамилии от имён и три «от зверей». Но в другой популяции это соотношение может быть инное. Например, на северо-западе почти все фамилии окажутся производными от имён. Это означает, что мы получаем в руки совершенно новую характеристику популяций, обогащаем свои знания и открываем новый метод. Такой семантический подход не имеет аналогий в анализе генов. Это характерная черта, особое богатство, свойственное анализу фамилий, благодаря тому, что они расцвечены красками языка и несут смысловую нагрузку. СЕМАНТИЧЕСКИЕ КЛАССЫ Фамилию можно отнести к одному из пяти классов. 1) «Календарные» - образованные от имён церковного календаря (например, Иванов, Феофанов). 2) «Профессиональные» - от названий профессий (Кузнецов, Колесников). 3) «Звериные» - от слов, описывающих животный и растительный мир (Волков, Жуков, Дубов, Листьев). 4) «Приметные» - от примет внешнего или психологического облика (Румянцев, Быстрое). 5) Фамилии, которые нельзя отнести ни к одному из этих классов (Морозов, Булыгин) выделяются в пятый класс «иные». Распределить фамилии даже по таким примитивным классам непросто. Не зная устаревших, диалектных или просто редких слов («бондарь» - делающий бочки, «саук» - Савва, «третьяк» - третий ребенок в семье) можно неправильно классифицировать Бондаренко, Саукова, Третьякова. А для многих фамилий этимология неоднозначна, запутанна и спорна. Так что классифицировать фамилии должен бы специалист по русской ономастике, но из-за неудач в поисках такового авторы решились классифицировать пока сами. Результаты, как часто бывает с анализом фамилий, превзошли ожидания. ФАМИЛЬНЫЕ ПРОФИЛИ РЕГИОНОВ Рассмотрев пятьдесят фамилий, самых частых в Центральном регионе «топ-50», мы обнаружили, что из них 25 - «звериные». То есть 50% фамилий приходится именно на один этот класс. В Западном регионе на один класс приходится ещё больше - 60% фамилий, но этот лидирующии класс включил вовсе не «звериные», а календарные фамилии. На Северо-Западе календарные фамилии совсем вытесняют остальные - там их 82%. А в Восточном регионе календарных только 14%, но зато как нигде часты приметные фамилии, которые делят первое место со «звериными» фамилиями. Так получилось, что каждый из остальных двух классов фамилий тоже имеет «свой» регион: профессиональные фамилии лидируют на юге (там их 34%), а «иные» - на севере (тоже 34%). Так что мнение о том, что самые русские фамилии - это Иванов, Петров и Сидоров (то есть календарные), справедливо только в западной части «исконного» ареала, и совсем неверно для востока и центра. Создаётся впечатление, что регионы различаются по способам образования фамилий - на юге чаще всего от профессий, в центре - «от зверей» и так далее. И каждый регион имеет свой характерный «фамильный профиль» - сколько фамилий приходится на долю каждого класса. Это не просто любопытное открытие, но и инструмент изучения генофонда. Посмотрим, например, на кубанских казаков. Их предки пришли из России и Украины, но откуда именно из России? Это вопрос о генофонде, и семантические классы фамилий могут дать предварительный ответ. Профиль фамилий кубанских казаков таков: Календарные - 34% Профессиональные - 22% Звериные - 16% Приметные - 14% Иные - 14%. Этот профиль больше всего похож на профиль соседнего с казаками Южного региона. Но фамилии показывают, что предки казаков переселялись не только оттуда. Отличия «казачьего» профиля от «южного» свидетельствуют, во-первых, о значительном потоке фамилий из среднерусских регионов, и, во-вторых, о последующей самостоятельной жизни казачьей популяции и о возникновении собственных неповторимых фамилий. Конечно, не стоит думать, что беглый анализ всего лишь по пяти классам фамилий явится откровением о происхождении кубанских казаков. Но это иллюстрация тех реальных возможностей, которые даёт семантический анализ фамилий. Ещё пример: как мы помним, статистический анализ показал, что фамильный фонд Сибири близок к среднерусскому - вероятно, по причине миграций из разных русских регионов. Семантический анализ добавляет, что особенно мощными могли быть миграции из самого географически отдалённого региона - с Запада: именно с «западным» профилем особенно схож «сибирский». ПЕРЕЧИСЛИМ МЕТОДЫ Для анализа фамилий мы применили не один-два, а веер практически независимых методов. Упорядочим их. 1) «ТОПЫ»: АНАЛИЗ САМЫХ ЧАСТЫХ ФАМИЛИЙ. В самых разных видах анализа нужно «перебрать» все фамилии - то сравнить их, то классифицировать, а сделать это вручную для многотысячных списков невозможно. Поэтому мы часто брали в анализ лишь несколько самых частых фамилий. Например, только что описанный анализ семантических классов выполнен по «топ-50»: в каждом регионе взяты 50 фамилий, самых частых в этом регионе, и только они классифицированы по семантике. Кроме «топ-50», использованы «топ-20», и даже «топ-10» и «топ-5» (только 5 самых частых фамилий). Несколько проверок показали что результаты, полученные по топ-50 и топ-20, обычно хорошо согласуются с анализом всего массива фамилий. Это значит, что использование только «топов» для многих видов анализа правомочно... Хотя, конечно, никогда заранее неизвестно, насколько большим должен быть «топ» чтобы дать правильный результат. 2) ПОИСК «ВСЕОБЩИХ» ФАМИЛИЙ. Раз мы имеем полные списки фамилий, встреченных в каждом регионе, мы можем посмотреть, насколько они перекрываются. Точнее: есть ли такие фамилии, которые встречаются в каждом регионе, существуют ли общерусские, повсеместные, «всеобщие» фамилии? При сравнении пяти регионов нашлось 257 таких фамилий. И есть основания думать, что после изучения других регионов этот список не сильно изменится - к нашему изумлению, при включении в анализ Сибирского региона этот список сократился только на 7 фамилий - а 250 фамилий (мы их привели в табл. 7.3.4.) оказались общими для всех шести регионов! В среднем, 13% из «коренных» фамилий, встреченных в каком-либо регионе, оказываются всеобщими, присутствуют и в других регионах. Это очень большая величина - раньше считалось, что таких фамилий почти нет, и поэтому сравнение удалённых регионов не имеет смысла, но к счастью, это оказалось не так. 3)ИНДЕКС МЕСТА. В общерусском списке все 67 тысяч фамилий мы расставили по убыванию их средней частоты. Значит, у каждой фамилии есть свой номер, её «ранг», её место среди всех русских фамилий. У группы фамилий тоже есть её «ранг» - среднее место входящих в неё фамилий. Именно эту величину мы и называем индексом места. Пользуемся мы ей часто - это просто и эффективно. Например, у нас есть список всех фамилий Западного региона, расположенных по их частоте в Западном регионе. Насколько этот список вторит «всеобщему»? Насколько «западные» фамилии совпадают со списком «всеобщих» фамилий? Чтобы ответить, нужно рассчитать индекс места для «западных» фамилий. Чтобы не считать индексы для тысяч фамилий, мы ограничиваемся расчётом для десяти самых частых фамилий. И эти показатели работают очень эффективно. 4)СРАВНЕНИЕ ПО ЧАСТОТАМ ФАМИЛИЙ. Здесь фамилии неотличимы от обычных генетических маркёров, и мы пользуемся обычными методами: рассчитываем генетические расстояния по частотам всех фамилий как бы по частотам аллелей, строим график многомерного шкалирования и так далее. Это позволило напрямую сравнить расстояния между регионами по частотам фамилий с расстояниями между популяциями из тех же регионов по частотам гаплогрупп Y хромосомы. Обнаружилась высокая корреляция (равная 0.6), доказывающая, что частоты фамилий достоверно свидетельствуют о «настоящем» сходстве популяций подобно «настоящим» генам. 5) СРАВНЕНИЕ ПО СЕМАНТИКЕ ФАМИЛИЙ. Мы уже говорили - такой анализ возможен только для фамилий. Каждая фамилия, встреченная в популяции, относится к тому или иному классу, и подсчитывается, какой процент фамилий приходится на каждый класс. Затем популяции сравниваются (на глазок или количественно) по полученным профилям классов фамилий. В этой книге мы классифицировали и сравнивали не все фамилии, а только «топ-50» каждого региона. 6) КАРТОГРАФИРОВАНИЕ ОТДЕЛЬНЫХ ФАМИЛИЙ. Здесь и статистический, и семантический подходы отходят в тень, и на сцене появляется карта - наш главный инструмент во всей книге. Картографирование фамилий ничем не отличается от картографирования распространения генов или любых других признаков. Неожиданно и приятно для исследователя, любящего фамилии, что даже в географии отдельных фамилий явно видны пространственные закономерности. Даже такая, казалось бы, вездесущая фамилия, как Иванов, оказывается отнюдь не вездесущей. Её зона обитания - запад и север «исконного» русского ареала, а, например, на юге она редка. Тем самым мы попутно опровергаем миф о случайном, повсеместном, недавнем и неинтересном возникновении русских фамилий от имён - ведь если бы миф был верен, Ивановы встречались бы с одной и той же частотой повсюду, где крестили по православному календарю. Раз фамилии картографируются так же, как и все остальное в геногеографии, значит с картами фамилий можно проводить дальнейший анализ - комбинировать их и в обобщённые карты главных компонент, и в карты инбридинга. 7)РАСЧЁТ СЛУЧАЙНОГО ИНБРИДИНГА. Это показатель весьма важный - он измеряет степень подразделённости популяций, и, кроме того, степень «огомозигочивания» (снижения гетерозиготности), что даёт прогноз груза рецессивных наследственных болезней. Этот традиционный для «фамильной генетики» расчёт мы провели для всех русских популяций. Результирующая карта показывает невысокие значения инбридинга на юге, и его возрастание к северо-востоку «исконного» русского ареала. ОТСЕВ РЕДКИХ ФАМИЛИЙ Наш обзор мы начали с числа 67 000 - именно столько обнаружилось русских фамилий. Но отражают ли они «только коренное» население, как требуется в геногеографии, обращенной к истории генофонда? При сборе генетических и антропологических данных мы спрашиваем каждого человека, где родились его родители и предки. Тех, кто происходит из данной местности («коренное население») мы включаем в выборку. А тех, у кого есть предки издалека - отсеиваем («пришлое население»). Так мы делим на коренное и на пришлое население при анализе генов. Но при анализе фамилий мы не можем опросить каждого из миллиона человек! Вместо прямого опроса, все исходные данные о фамилиях мы пропустили через сито демографического критерия. В результате из примерно миллиона человек осталось около 700 тысяч человек - остальные триста тысяч оказались носителями фамилий, которые нигде, ни в одном районе не достигают численности даже в пять человек. Эти фамилии мы расцениваем как вероятно «пришлые» в изученных популяциях, а потому неинформативные для анализа коренного населения. Таких фамилий оказалось очень много: из 67 тысяч отсеялось пятьдесят три тысячи! Осталось лишь 14 тысяч фамилий, которые мы расцениваем как коренные - и только эти фамилии используются в большинстве видов анализа. Стоит задуматься, не слишком ли много мы потеряли при таком отсеве? Скорее всего, нет. Ведь хотя мы отсеяли 75% фамилий, но общее число человек снизилось только на 25%. Именно потому, что эти фамилии очень редкие, их носителей не так много. Не включая их в анализ, мы скорее избавляемся от случайных помех, чем теряем ценную информацию о генофонде. Ведь наша цель - изучение фамилий не ради них самих, а ради изучения генофонда. ФАМИЛИИ НЕ РАДИ ФАМИЛИЙ Начиная наше изучение русских фамилий, мы стремились получить новые знания о структуре русского генофонда. Однако в процессе изучения обнаруживалось столько любопытных и удивительных свойств фамилий, что наше исследование стало во многом методическим: мы освоились с таким типом маркёров как фамилии, придумали и опробовали новые методы их анализа. Теперь пора оглянуться и посмотреть, какие же конкретные знания о русском генофонде это нам дало. Главным является, пожалуй, информация о степени сходства разных регионов: сходство популяций среднерусской полосы, особость юга и севера. Важны и данные о Сибири: отсутствие своеобразия генофонда современного русского населения Сибири, его приближённость к усреднённому русскому генофонду, и в особенности к регионам средней полосы, и из них в первую очередь к Западному. Карта инбридинга - второй важный результат - показывает его возрастание к северу и востоку. Значит, именно в этом направлении растёт подразделённость русского генофонда - восточные и северные популяции более изолированы друг от друга, и вероятно, меньше по численности и занимаемому ареалу, чем популяции того же ранга на западе и юге. Наконец, третьим важнейшим результатом стали карты главных компонент. Для прочих типов признаков (классических маркёров, антропологии, Y хромосомы) карты главных компонент были главным обобщающим результатом. Теперь и фамилии встают в строй, становясь ещё одним очевидцем в «мультио-кулярном» подходе, ещё одним свидетелем структуры генофонда. И карты главных компонент фамилий тоже показывают нам изменчивость, близкую к широтной, не противореча остальным свидетелям. Но в отличие от главных компонент по остальным системам, главные компоненты фамилий куда более своеобразны. Это вызвано, прежде всего, тем, что анализ главных компонент мы смогли провести лишь по 75 фамилиям, а среди этих фамилий непропорционально много «календарных» и слишком мало фамилий, характерных для северного и южного регионов. Скорее всего, именно поэтому широтная изменчивость на картах фамилий оказалась затушёвана. Это окончательно прояснится в будущем, когда мы изучим недостающие регионы и сможем построить главные компоненты не по 75, а по всему множеству фамилий. Пока же первая главная компонента изменчивости фамилий выявляет распространение именно календарных фамилий. Именно они вносят основной вклад в первую компоненту, которая, как и календарные фамилии, сильно смещена к западу. ЧТО ДАЮТ ФАМИЛИИ? Что же нам дало изучение русских фамилий? Мы не будем повторять все те результаты, которые касаются фамилий как таковых. Мы посмотрим, что это дало для изучения русского генофонда. Во-первых, фамилии оказались ещё одним - и парадоксально надёжным! - источником сведений о структуре генофонда. Они подтвердили различия между южными и северными русскими популяциями при меньших различиях между западными и восточными. При анализе других систем этот вывод следовал из главных компонент. При анализе фамилий он угадывается в компонентах и ясно виден на графиках сходства регионов. Фамилии дали дополнительную информацию и по многим более частным вопросам, уточняя и проясняя структуру русского генофонда. Но, во-вторых, и в главных, «показания» фамилий оказались удивительно сходными с показаниями генов. Чего стоит, например, одна лишь высокая корреляция (г=0.6) между матрицами расстояний по фамилиям и по гаплогруппам Y хромосомы! Это неизменное сходство результатов, полученных по фамилиям и по генам, подводит к новому подходу, новому плану использования фамилий: сначала разведка структуры генофонда с помощью фамилий - и лишь затем планирование собственно генетических исследований. Ведь фамилии можно изучить тотально - для всех популяций, а в популяции для каждого человека. То есть сделать именно то, что невозможно сделать по генам. Поэтому можно сперва провести разведку боем: изучить структуру генофонда по данным о фамилиях, выявить основные закономерности, основные «кластеры» популяций - и уже по этим данным планировать изучение генофонда по генетическим маркёрам. Например, разумно было бы изучать по одной популяции из каждого кластера, выявленного фамилиями, чтобы охватить основное разнообразие генофонда. Тем самым фамилии не дадут упустить при генетическом обследовании ни одну из своеобразных, отличающихся групп. А именно эта опасность - постоянная головная боль полевого исследователя генофонда. Можно предложить и ещё одно яркое применение фамилий - для изучения переселенческих генофондов. Предположим, какая-то группа населения сформировалась за счёт миграций из нескольких источников, нескольких «материнских» групп. И, зная частоты генов в материнских группах и располагая данными по фамилиям, мы можем узнать частоты генов в переселенческой группе, не изучая её! Для этого нужно по данным о фамилиях установить, какие группы являлись материнскими и в каком соотношении они смешались в переселенческой группе. А дальше остаётся усреднить частоты генов в материнских популяциях, взвесив их на полученные по фамилиям «коэффициенты миграции» в переселенческую группу. Конечно же, польза от фамилий не исчерпывается помощью в планировании исследований для генетики или в изучении «переселенческих» генофондов. Главным результатом своей работы с фамилиями авторы хотели бы видеть широкое распространение этого типа маркёров и в теории, и в практике исследований разных генофондов. 3 d - традиционное в популяционной генетике обозначение для генетического расстояния (от англ. distance). Нижний индекс указывает, между какими именно регионами вычислено расстояние. Например, dN-S - это расстояние между Северным (Northern) и Южным (Southern) регионами; dW-E- это расстояние между Западным (Western) и Восточным (Eastern) регионами; dN-C - это расстояние между Северным (Northern) и Центральным (Central) регионами; a dN - средние расстояния от Северного региона (черта над символом - общепринятое в статистике обозначение для средней величины). |
загрузка...