5.1. Общие вопросы и «классические» ответы
|
§1. Смещены ли оценки разнообразия по классическим маркёрам? Описывают генофонд - Подробно изучены - Смещение оценок - миф! - Но живучий
§2. Зачем нужны карты? У каждого гена свои популяции - Статистик отрубит неизученное - Картограф изучит недоизученное - Искать закономерности в толпе цифр? - Лучше увидеть их на карте! §3. Кого изучать? Только «исконный» ареал - Все его части - Коренные популяции - Коренные семьи - Правило третьего поколения - Одного из семьи §4. Как устроены карты? Построение карты - Анализ карты - Выбор генов для атласа — Сорок четыре карты - Шагреневая кожа надёжного ареала. §5. Что мы увидим на картах? Исходные данные и карты - Карты точнее! - Фактор числа точек - Фактор неравенства ареалов — Замечаем действие отбора — По отклонению от селективно-нейтральной изменчивости — Замечаем действие истории - По величине селективно-нейтральной изменчивости — А также по рельефу карты - Сфинкс §6. Иерархия популяций: «матрёшки». В ойкумену вложены регионы - В регионах этносы - В этносах локальные популяции - Промежуточные матрёшки - Такова модель генофонда - Частота в локальной популяции - Этническая частота как средняя локальных - Региональная как средняя этнических - Но никак не средняя всех локальных! - Дисперсия локальных частот -Дисперсия этнических частот - Когда внутриэтническая нулевая - Можно прыгать через матрёшку - Но лучше проходить их все подряд - Всё это важно знать! В этом разделе мы объединили общие вопросы, которые всегда возникают при изучении генофонда. На многие из этих вопросов из всех разнообразных генетических маркёров пока могут дать ответ именно классические маркёры. §1. Смещены ли оценки разнообразия по классическим маркёрам?КЛАССИЧЕСКИЕ МАРКЁРЫ Классическими маркёрами принято называть гены, изучаемые не по их строению, а по их проявлению на уровне белков, на уровне фенотипа. Поэтому к группе «классических» маркёров (см. главу 1) относят все те многообразные генетические маркёры, с которыми работала популяционная генетика до наступления «ДНК-эры». Это и иммунологические маркёры, в длинный список которых входят всем известные группы крови (АВ0, Резус). Это и физиологические маркёры - генетически заданные особенности ощущения цвета и вкуса. Это и генетико-биохимические маркёры - различные ферменты эритроцитов и сыворотки крови (изредка - других тканей). Все эти признаки объединяет то, что по их фенотипическому полиморфизму (разным проявлениям у разных людей) можно однозначно судить о генетическом полиморфизме - о конкретных вариантах генов (генотипах этих людей). Поэтому эти признаки фенотипа и называются генетическими маркёрами - ведь они маркируют гены, то есть дают нам знать, какой аллельный вариант гена скрывается за данным внешним проявлением признака. И классические маркёры, и антропологические признаки мы определяем по их проявлению, по фенотипу. Однако разница есть, и немаловажная. Изучая антропологические признаки, мы знали, что за ними скрываются группы генов, но не знали - какие именно, не могли назвать эти гены по именам, узнать их «в лицо», не могли извлечь чисто генетическую информацию. Переходя к классическим маркёрам, мы переходим к столь простым признакам, что за каждый из них отвечает всего лишь один ген. Считается, что у классических генных маркёров путь от гена до признака столь невелик, что другие гены (или условия среды) не успевают вмешаться в результаты работы гена. И поэтому по внешнему проявлению, по фенотипу мы можем однозначно судить о генотипе. Следовательно, по множеству классических маркёров мы можем восстанавливать структуру самого генофонда, а не его преломление в фенофонде, как по признакам антропологии. В следующей главе мы сделаем ещё один шаг и рассмотрим генетический портрет русского генофонда уже по молекулярно-генетическим (ДНК) маркёрам. Для них нам уже не надо будет знать даже фенотипического проявления генов - многие из ДНК маркёров такого проявления и не имеют. Для ДНК маркёров мы напрямую отслеживаем изменения самого генетического материала. Это проще и удобнее. Однако пока наиболее изученные в русских популяциях ДНК маркёры, на которые можно опереться - это гаплогруппы митохондриальной ДНК и Y хромосомы (глава 6). Но при всех их достоинствах, только двух - и столь своеобычных! - генных локусов явно недостаточно для изучения всего генофонда. Поэтому до тех пор, пока не накопится достаточно данных по остальным ДНК маркёрам, наиболее надёжные данные о русском генофонде можно добыть, только опираясь на классические маркёры. ОЦЕНКА РАЗНООБРАЗИЯ ГЕНОФОНДА «Нет в мире совершенства» - справедливо считал Лис [Сент-Экзюпери, «Маленький принц»]. Наверное, и у классических маркёров есть изъяны? Надо сразу сказать, что основной упрёк классическим маркёрам - смещение оценок разнообразия относительно всего генофонда - оказался несправедливым. Этот упрёк основывался на том, что классические маркёры тестируются по их белковым продуктам, которые обычно подпадают под действие естественного отбора. А ДНК маркёры тестируются прямо по нуклеотидным последовательностям, которые могут быть не подвержены отбору. И предполагалось, что из-за действия отбора различия между популяциями, рассчитанные по классическим маркёрам, искажены. Поэтому на заре «ДНК эры» широко распространилось мнение, что пора отрешиться от анализа генофонда по классическим маркёрам! Оказалось, что этот шаг поспешен и неверен - классические маркёры точно и правильно оценивают разнообразие генофонда. В действительности, предположение, что классические маркёры дают искажённую оценку, неверно даже теоретически: ещё до появления первых оценок по ДНК маркёрам нами теоретически было показано, что среднее разнообразие популяций GST должно быть одинаково и по ДНК, и по классическим маркёрам [Рычков, Балановская, 1987, 19906]. Самая первая работа по межпопуляционной изменчивости ДНК маркёров, осуществленная коллективом L. L. Cavalli-Sforza ([Bowcock et al., 1987], см. подробно Приложение) подтвердила этот прогноз. И с тех пор все корректно проведённые сравнительные исследования давали тот же результат (см. Приложение и главу 8): полное соответствие межпопуляционной изменчивости, рассчитанной по классическим и по аутосомным ДНК маркёрам. Уж скоро минет пятнадцать лет, как с классических маркёров было полностью «снято обвинение» в смещённости оценок [Bowcock et al., 1987; 1991а; Bowcock, Cavalli-Sforza, 1991; Cavalli-Sforza, Piazza, 1993]. И, тем не менее, до сих пор из диссертации в диссертацию кочует поверье, что по классическим маркёрам разнообразие не определишь. Научные мифы живучи. И эхо необдуманных предсказаний может десятилетиями тормозить развитие науки. До сих пор многие учёные, работающие с ДНК маркёрами, из-за этого поверья считают себя вправе не знать всё, чго было получено по классическим маркёрам их предшественниками. Образовавшийся разрыв в преемственности науки создаёт ту свободу от прошлого, которая рождает легковесность и необязательность утверждений: «Свобода веток от ствола и корня, свобода плеч от тяжкой головы...».1 §2. Зачем нужны карты?НЕРАВНОМЕРНОСТЬ ИЗУЧЕННОСТИ Итак, упрёк в смещённости оценок разнообразия оказался неоправданным. Однако у классических маркёров всё же есть существенный изъян, хотя совсем иной - это крайняя неравномерность их изученности. Антропологические маркёры, как мы видели в главе 4, исследованы в большинстве популяций по единой программе - это обеспечивает полную сопоставимость популяций по всему набору признаков. По панелям однородительских ДНК маркёров также многие популяции изучены идентично. А по классическим маркёрам и аутосомным ДНК маркёрам программа исследований не была стандартизирована: в одних популяциях изучались одни маркёры, в других популяциях - другие маркёры. Если составить сводную таблицу, то мы увидим, что для каждой популяции изучен свой набор маркёров, а для каждого из маркёров изучен свой набор популяций. Это делает популяционную информацию по классическим маркёрам плохо сопоставимой. Например, наше геногеографическое изучение генофонда Восточной Европы (глава 8) опирается на данные по 100 аллелям (34 локусов) в 1586 популяциях. Но ни одна из полутора тысяч популяций не изучена по всем 34 генам. Поэтому напрямую провести статистический анализ невозможно: в матрице 1586 х 100 большинство ячеек пустуют. Эта проблема несопоставимости данных по разным популяциям постоянно возникает при анализе классических маркёров и затрудняет использование методов многомерного статистического анализа - главных компонент, генетических расстояний и так далее. ГОРДИЕВ УЗЕЛ Обычный выход из этой ситуации - резкое сокращение числа анализируемых популяций и числа анализируемых генов. В результате в анализ включаются лишь немногие подробно изученные популяции и немногие общепринятые маркёры Например, из матрицы 1586 х 100 останутся в лучшем случае только 20 х 8, но зато все ячейки будут заполнены - каждая из 20 оставшихся популяций изучена по каждому из 8 аллелей. Решение простое. Оно уничтожает не только проблему, но и информацию, с трудом собранную поколениями генетиков. Такой способ обращения с гордиевыми узлами могут позволить себе полководцы, а не исследователи. «Македонское решение» приводит к анализу лишь малой части всего генофонда и, следовательно, к малой надёжности результатов. Ведь несколько случайных популяций, которым посчастливилось быть изученным по этой панели маркёров, не могут надёжно представлять всю популяционную систему. А малый набор маркёров также не может служить характеристикой генофонда. В этом случае анализируется лишь случайный ряд популяций по нескольким генам, но не сам генофонд. Иной - «не македонский» - выход из этой ситуации даёт геногеография. Она осторожно распутывает гордиевы узлы классических и аутосомных ДНК маркёров. По сведениям о популяциях, изученных по данному аллелю, геногеограф прогнозирует частоту этого аллеля в остальных, «пропущенных» популяциях. Специальные процедуры картографической интерполяции помогают найти наиболее вероятные значения признака для тех популяций, по которым исходная информация отсутствует. В результате заполняются «пробелы» вырожденной матрицы и в анализ включаются все изученные популяции и репрезентативный набор генных маркёров. Карты «надёжности» [Нурбаев, Балановская, 1997, 1998] позволяют выбрать из всей совокупности интерполированных (прогнозируемых) значений лишь те, которые обладают высокой надёжностью (см. Приложение). ОБЪЕКТИВНОСТЬ КАРТЫ Есть и ещё одно важное достоинство карт. Сравним таблицу исходных данных и карту, построенную на её основе. Сводку всех основных данных по изменчивости классических генных маркёров в русских популяциях мы привели в Приложении (раздел 6) и на сайте www. genofond.ru. Однако читатель, заглянув туда, сразу убедится, сколь непросто проследить по этим табличным данным географические закономерности. Такая задача не по плечу порой даже специалистам, всю жизнь имеющим дело с этими генами. Надо не только удержать в уме массу цифр, не только точно соотнести их в уме с географическим пространством, но ещё и забыть о своих априорных представлениях и ранее высказанных гипотезах. Каждый из нас представляет, сколь это сложно. Поэтому разные учёные могут увидеть в одной и той же таблице совершенно разные географические закономерности. И как решить, кто из них прав? Другое дело - карта. На карте отчётливо видны те географические закономерности, которые так сложно было увидеть, рассматривая таблицу. Здесь вновь приходит на помощь компьютерная картография. Её технологии дадут объективные зримые образы географической изменчивости гена, покажут основные направления роста и падения частоты аллеля, рассчитают связь с широтой, долготой, с другими признаками [Балановская и др., 1994а, 19946; 1999; Балановская, Нурбаев, 1995, 1999; Кравчук и др., 1998; Балановский и др., 1999]. Такие карты позволят и коллегам из любых смежных областей «на равных» с генетиками обсуждать особенности пространственной изменчивости генов, не погружаясь при этом в генетическую терминологию и специфику. Особенно важно, что компьютерная геногеография сводит к минимуму субъективный момент: она обеспечивает полную воспроизводимость карт, позволяет карты всех генов построить одним и тем же способом, проанализировать одними и теми же статистическими методами, объективно сравнить карты разных генов. Именно так в основном разделе 5.2. данной главы рассмотрены карты изменчивости различных генов в ареале русского генофонда. Цель такого рассмотрения проста - привести карты распространения наиболее изученных конкретных генов, дать их краткое описание; а при наличии ярких закономерностей генетического рельефа - предложить гипотезы, объясняющие факторы его формирования. §3. Кого изучать?- Сколько дипломов надо иметь, чтобы считаться интеллигентным человеком? - Нужны три диплома о высшем образовании: дедушкин, папин и свой собственный. Поскольку мы перешли к «настоящим» генетическим маркёрам, перечислим первые вопросы, которые следует задать при создании их картографического атласа. В пределах какого ареала нужно изучить генофонд данного народа? Какая территория может считаться этническим ареалом при исследовании его истории? Какие необходимо изучить популяции, чтобы выявить реальные генетические различия в пределах ареала? Каковы должны быть выборки? Иными словами, какие части этнического ареала и какие части населения мы непременно должны изучить, чтобы выявить реальную структуру генофонда? Перечисленные ниже правила формирования выборок относятся не только к классическим - к любым генетическим маркёрам. ТОЛЬКО «КОРЕННОЕ» НАСЕЛЕНИЕ В подавляющем большинстве геногеографических исследований - не только наших, но и в мировой науке - используется принцип изучения «только коренного населения». Он включает несколько правил, которые помогают решить: какие ареалы, какие популяции и каких именно индивидов стоит включить в обследование, чтобы удалось реконструировать историю генофонда? Расскажем о некоторых из этих правил. ПРАВИЛО ПЕРВОЕ: ИСТОРИЧЕСКИЙ АРЕАЛ ЭТНОСА Этим правилом задаётся круг генетически обследуемых популяций. Обычно анализируются только популяции в пределах «исконного» ареала этноса, то есть той территории, на которой этот народ исторически сформировался. Подчеркнём: границы «исконных» этнических ареалов определяются не генетиками, а специалистами в области этнографии, лингвистики и других гуманитарных наук. Генетики всегда только используют данные гуманитарных наук и никогда не определяют «исконность» ареала по данным генетики! Не потому, что не хотят (кто-то, может быть, и захочет...) - а потому, что это невозможно по определению. Для определения «исконного» ареала не так важно, что народ после своего формирования мог расширить, сузить или сменить территорию расселения. Примером могут служить адыги, после Кавказской войны переселившиеся не только в Турцию, но и во многие страны Передней Азии, Ближнего Востока и даже Мадагаскара. Однако их «исконный» ареал по-прежнему остается на Западном Кавказе, несмотря на то, что ныне там плотность славянского населения намного превышает плотность коренных народов. Важно учесть и то, что набор анализируемых популяций должен представлять все основные части этнического ареала. Если все изучаемые популяции будут сосредоточены лишь в одной части ареала (например, все изученные русские популяции будут только из Саратовской области), то мы получим характеристику не всего народа, а лишь изученной части (подменим русский генофонд генофондом русских Поволжья). ПРАВИЛО ВТОРОЕ: АРЕАЛ ПОПУЛЯЦИИ Этим правилом задаётся круг населённых пунктов, которых можно изучить для характеристики локальной популяции, принадлежащей к данному этносу и живущей в пределах его исторического ареала. Например, в нашей экспедиционной работе из всех населённых пунктов в пределах изучаемой популяции обследуются те, которые в наименьшей степени были подвержены влиянию миграций и потому могли сохранить наиболее древний, коренной генофонд. Для выполнения этого правила необходимо каждый раз чётко формулировать, какая именно популяция представляет интерес для изучения генофонда. И уже в пределах её ареала отбирать индивидов для включения в выборку. Например, если мы хотим изучить популяцию коренного населения Краснодарского края, то корректнее изучить не всё проживающее там русское население, а только потомков кубанских казаков. Они могли сохранить те генетические черты, которые помогут реконструировать веками складывавшуюся структуру русского генофонда. Современное же население Краснодарского края (в котором потомки кубанских казаков составляют лишь очень малую часть) из-за мощных ветров миграций скорее внесёт путаницу в деле реконструкции истории генофонда. Поэтому для изучения истории русского народа в выборку индивидов, представляющих Краснодарский край, мы включили только потомков кубанских казаков. Если же встанет иная задача - изучение недавних событий в русском генофонде - то правила выбора индивидов и ареала, из которого они должны происходить, станут совсем иными. Если нам потребуется изучить «мгновенный» (сиюминутный, эфемерный) срез генофонда Краснодарского края - мы должны будем обеспечить создание такой выборки. Но даже в этом случае нельзя брать первых попавшихся представителей населения края - они не создадут случайную репрезентативную выборку даже для «сиюминутного» среза. Ведь всё будет зависеть, где эти люди нам «попались» - ведь та часть края (или та поликлиника, в которой мы решили собирать выборку) может быть совершенно отличной от реальной структуры генофонда. Например, если мы организуем наш сбор образцов в аэропорту, всё будет зависеть, откуда или куда отправлялись в «сию минуту» самолеты. ПРАВИЛО ТРЕТЬЕ: «ПРАВИЛО ТРЁХ ПОКОЛЕНИЙ» При изучении истории русского генофонда мы старались следовать «правилу трёх поколений»: включению в выборку только тех индивидов, ВСЕ предки которых до третьего поколения (все бабушки и деды) не только относились к данному этносу, но и родились в пределах ареала данной популяции. Конечно, для этого надо составлять родословные. Соблюдение этого требования позволяет избежать влияния недавних миграций. Следуя ему, мы исключаем из генетико-исторического исследования, например, тех людей, чьи родители переселились на эту территорию из иных областей. Пока ещё неизвестно, оставят ли они свой генетический след в популяции? Поэтому «правило трёх поколений» позволяет учесть только те миграции, которые уже оставили реальный след в генофонде (например, ныне многочисленных потомков семьи, переселившейся на изучаемую территорию столетие назад). Применение этого правила можно проиллюстрировать следующим примером. При изучении генофонда Псковской области мы выбрали для обследования две популяции, в которых и ныне сохраняется коренное население и которые достаточно полно представляют сложную историю русского населения Псковской земли: отражают и собственно псковское, и новгородское население. Первая популяция - Островский район, собственно псковитяне. И обследуя её, мы формируем выборку так, чтобы в нее попали только те индивиды, все бабушки и дедушки которых родились в Островском районе. Вторая популяция - Порховский и Дедовический районы - сначала входили в земли Новгородские, и лишь после падения Новгорода отошли ко Пскову. Поскольку оба района (и Порховский, и Дедовический) представляют популяцию с единой историей и в равной степени отражают интересующее нас население, то, обследуя эту популяцию, мы формируем выборку так, чтобы в нее попали только те индивиды, все бабушки и дедушки которых родились в пределах этих двух районов (Порховского и Дедовического). В этом случае мы не требуем принадлежности предков к одному району, как в случае Островского района - а к любому из двух, соседних и исторически сходных. Этот пример показывает, что выбор популяций определяется целиком историей формирования народа - не имея возможности генетически изучить все популяции, мы выбираем для анализа ключевые для понимания истории и структуры генофонда. Ареал изучаемой популяции в первом примере равен одному району, а во втором - двум. ПРАВИЛО ЧЕТВЁРТОЕ: ИСКЛЮЧЕНИЕ РОДСТВА Родословные надо знать и для того, чтобы не включать в выборку родственников - родство между индивидами в выборке также исключается до третьего поколения. Например, если на обследование пришли два индивида, и обнаружилось, что их бабушки или дедушки являются друг другу братьями или сестрами, то мы включаем в выборку лишь одного из двух пришедших. Это и понятно - если мы включим в выборку родственников, то повторно возьмём одни и те же гены. Из-за этого реальная выборка становится меньше, да к тому же может произойти «смещение» частот генов популяции в сторону какой-либо семьи. В русских селах такое смещение может произойти даже тогда, когда мы обследуем только один край села - ведь родственники чаще селятся рядом. ПОПУЛЯЦИИ ДЛЯ АНАЛИЗА КЛАССИЧЕСКИХ МАРКЕРОВ При картографировании классических маркёров в русских популяциях мы сочли возможным - в порядке эксперимента - несколько отклониться от буквы первого из правил. В историческую территорию формирования и «исконного» расселения русского народа никак не могут быть включены территории Прибалтики, Причерноморья, Предкавказья, Нижней Волги, Приуралья, не говоря об Урале и Кавказе. С другой стороны, последние столетия характеризуются массовым распространением русского населения на этих обширных территориях, их смешением с автохтонным населением и даже формированием новых популяционных образований (например, камчадалы, изоляты сибирских староверов, Ленские старожилы и др.). Поэтому в анализ мы включили данные не только по территории формирования русского народа, но и некоторые популяции из смежных областей, оставаясь при этом в пределах Восточной Европы. Результаты такого эксперимента подробно описываются во многих разделах данной главы. Мы отобрали для анализа русские популяции, расположенные от 43° до 70° северной широты и от 24° до 60° восточной долготы2. При всей условности такого отбора данных, он позволил автоматически исключить из рассмотрения многие территории, оторванные от основного ареала. Хотя при этом мы несколько вышли за пределы «исконного» ареала, подчеркнём, что только такая особенность русского народа, как его массовое расселение на огромных территориях Евразии, вынудила нас рассматривать, строго говоря, и некоторые «некоренные» популяции. В заданную область пространства попадает небольшая часть территории соседних с Россией государств - Прибалтики, Белоруссии, Украины. Однако особо подчеркнём: только русское население этих территорий включалось в анализ! Так что и в статистическом анализе, и на картах русского генофонда присутствуют только русские популяции, расположенные в пределах заданной области. ИНДИВИДЫ ДЛЯ АНАЛИЗА КЛАССИЧЕСКИХ МАРКЕРОВ Что же касается третьего правила (формирование выборки индивидов), то здесь мы ограничены подходом авторов, публикации которых использованы при создании Банка данных о русском генофонде. В отечественных генетических исследованиях выборка из популяции обычно составляется из неродственных лиц, которые рождены на данной территории и родители которых относятся к данному этносу. Некоторые авторы, к сожалению, определяли принадлежность к популяции и этносу лишь по происхождению самого индивида, а не его предков. Однако многие другие авторы собирали данные много тщательнее - учитывались места рождения и этническая принадлежность всех четырех бабушек и дедушек пробанда. Это позволяло избежать случайных колебаний миграционного потока и учесть в выборке только наиболее устойчивые миграции, генетический след которых сохранился в популяции и по прошествии двух поколений. Именно такие выборки дают наиболее полное представление об исторически сложившейся структуре генофонда. §4. Как устроены карты?Главным «прибором», показывающим структуру русского генофонда, служат геногеографические карты. Технология создания карт достаточно подробно описана в Приложении. Для читателя, не заглядывающего в другие разделы, кратко повторим основные моменты, необходимые для лёгкого чтения и понимания карт, приведённых в этой главе и всей второй части книги. СТРОИМ КАРТУ Для построения карты используется информация об изученных русских популяциях. Каждая из этих популяций служит «опорной точкой». По совокупности опорных точек рассчитываются значения частоты аллеля в каждой точке карты. Для карт классических маркёров число изученных популяций (опорных точек - К) варьирует от 8 (локус HLA*B) до 182 (группы крови АВ0). Число же точек карты (узлов сетки) очень велико - 9064, и значение в каждой точке карты рассчитывается по данным обо всей совокупности опорных точек (К) - исходных популяций, изученных по данному маркёру. Географическое положение опорных точек указано (тёмными кружками с белым обрамлением) на самой карте. Понятно, что в тех областях карты, где опорных точек много, можно получить надёжно прогнозируемые значения во всех узлах сетки, во всех точках этой области. А там, где опорных точек мало (например, в периферийных областях карты), рассчитанные значения в узлах сетки карты будут ненадёжны. Такие «ненадёжные» точки карты мы не анализируем. Поэтому, хотя общее число узлов сетки одинаково для всех карт русского генофонда (9064 точек), число надёжных точек намного меньше - от 895 (локус KEL) до 4355 (локус АВ0). Именно это число - число надёжных точек карты - указано в легенде карты (N). Только эти точки отображаются на карте и включаются в любые виды статистического анализа. Число опорных точек (К) также приведено в легенде карты. Чтобы карта была информативна, важно легко на ней ориентироваться, соотносить выявляемые зоны генетического рельефа с другими географическими объектами - странами, областями, городами, реками, природными зонами, этническими ареалами и так далее. Для этого на всех картах приведены береговые линии морей и гидрографическая сеть (озера, реки), горные хребты, государственные границы, несколько крупных городов (значимых, согласно замыслу книги, скорее для средневековой, чем современной, России), а самой надёжной привязкой карты к реальному географическому пространству служит, разумеется, градусная сетка. ЦИФРОВАЯ МОДЕЛЬ КАРТЫ. Процедуры построения и анализа компьютерных карт подробно описаны в Приложении. Здесь напомним лишь, что в основе компьютерных карт лежат их цифровые модели (ЦМ) - двумерные числовые матрицы частот аллеля, а значения частоты аллеля прогнозируются для каждого узла сетки карты. Для создания такой матрицы пространство карты было покрыто густой равномерной сетью, состоящей из 9064 узлов. Для каждого узла сетки с помощью интерполяционной процедуры рассчитано значение частоты аллеля. В расчёте значений каждого узла участвовали все изученные русские популяции в пределах заданного радиуса, взятые с весом, обратным расстоянию от популяции до данного узла сетки. Параметры картографирования для русского генофонда: использована нулевая степень полинома, шестая степень весовой функции и учитывалась информация об исходных популяциях в радиусе 2000 км. Такой расчёт проводился независимо для каждого узла сетки. Это означает, что для каждого из 9064 узлов сетки учитывались одни и те же опорные точки (реально изученные популяции), но расстояния до популяций и, следовательно, вес каждой популяции при определении частоты аллеля в данном узле сетки - менялись. Часто спрашивают: зависит ли карта от того, с какого угла мы начнём её строить? Еще раз подчеркнём - рассчитанные значения в каких-либо узлах сетки никак не влияют на определение частоты аллеля в других её узлах. Отвечаем на вопрос: поэтому-то совершенно неважно, откуда мы начнём и в каком порядке будем проводить расчёт для разных узлов карты. СОЗДАНИЕ ИЗОБРАЖЕНИЯ. Но цифровая модель - это матрица, таблица. Чтобы отобразить сё в виде карты, каждое значение окрашивается своим цветом - в зависимости от того, в какой из интервалов попадает это значение. Шкала интервалов задаётся исследователем-автором карты. Понятно, что образ одной и той же карты (одной и той же ЦМ) может различаться в зависимости от избранной шкалы. Поэтому так важно следовать определённым правилам выбора шкалы (см. Приложение). Шкала обязательно приводится в легенде каждой карты. Граничные значения интервалов шкалы приводятся под гистограммой. Сама гистограмма и числа над столбцами гистограммы указывают долю площади карты, занятой точками, значения в которых попали в данный интервал. НАДЁЖНОСТЬ. Карта каждого аллеля сопровождается специальной картой надёжности - она для каждого узла сетки указывает достоверность рассчитанного значения частоты аллеля [Нурбаев, Балановская, 1998]. Значения принимались как достоверные, когда вероятность правильного прогноза составляла Р>0.95 при уровне строгости3 r = 0.3. «Ненадёжные», то есть слабоизученные области, залиты на картах белым цветом и заточкованы, и все характеристики карты рассчитываются только по надёжному пространству. Число узлов карты (N), вошедших в «надёжное пространство» данного аллеля, указано в легенде каждой карты. После того, как для каждого «надёжного» узла сетки получен независимый прогноз частоты аллеля, создание цифровой модели (ЦМ) карты завершено. Далее с ЦМ (как с обычными матрицами) проводим все дальнейшие преобразования и статистические расчёты - корреляций, трендов, главных компонент, получая количественные оценки связей и закономерностей. При этом карта, содержащая прогнозированные значения для каждой точки, становится не иллюстрацией, а математической моделью пространственной изменчивости. Карта служит инструментом количественного анализа генофонда. Это значит, что карта становится не «графическим», а «алгебраическим» объектом. КОРРЕЛЯЦИИ. Связь частоты аллеля с широтой и долготой оценивалась не только обычным - единственным - значением коэффициента корреляции, но ещё и строились три корреляционных карты. Одна такая карта содержала в каждом узле показатели корреляции значения признака с широтой. Другая - с долготой. Третья - показатель множественной корреляции с широтой и долготой. Среднее значение корреляции по всем точкам карты является аналогом обычного коэффициента корреляции. Сама же карта показывает, какова теснота связи в том или ином регионе, в той или иной части карты. Ведь вполне возможна ситуация, когда в одном регионе изменчивость аллеля широтна, а в другом - коррелирует с долготой. Более того, при переходе от региона к региону может измениться даже знак корреляции. В этом случае обычный коэффициент корреляции неэффективен, и реально существующую закономерность может выявить только корреляционная карта. Для построения корреляционных карт используется разработанная нами процедура «плывущего окна» (см. Приложение, а также [Балановская и др., 1994а.б; Балановская, Нурбаев, 1995]). В каждом узле сетки указан показатель корреляции, рассчитанный для «плывущего окна» - области карты заданной площади, в центре которой находится данный узел. Иными словами, для совокупности всех узлов сетки, попавших в это «окно», рассчитывался коэффициент корреляции между частотой аллеля в этих точках и географическими координатами (широтой, долготой) этих точек. И полученное значение коэффициента корреляции заносилось в центральный узел окна. Затем окно перемещалось на один узел сетки, и операция повторялась. После того, как окно «проплыло» по всей карте и все ее узлы побывали центральными, каждый из «надёжных» узлов получил свое значение корреляции признаков. Из этих значений построена карта корреляций, показывающая, как меняется уровень связи (корреляции) в различных частях карты. В таблице 5.2.1 приведены MIN, MEAN, МАХ, - соответственно минимальное, среднее и максимальное значения коэффициента корреляции. Напомним, что в статистике коэффициенты частной корреляции меняются от -1 до +1, а множественные - всегда положительны (от 0 до 1). ТРЕНДЫ. Для большей простоты и наглядности в работе приведены карты, полученные при небольшом окне сглаживания (фоновые карты или «карты трендов», см. Приложение, а также [Балановская, Нурбаев, 1995]). Эти карты, также как и корреляционные, получены с помощью процедуры «плывущего окна». Только в центральный узел заносились не коэффициенты корреляции, а средняя частота по всем узлам сетки, попавшим в «плывущее» окно. В результате «сглаживались» резкие колебания частоты гена - ведь такие колебания частоты между соседними популяциями обычно связаны с несовершенством популяционных выборок. В таблице 5.2.1. и в легендах соответствующих карт раздела 5.2 приведены статистические характеристики исходного (несглаженного) генетического рельефа. СТАТИСТИКИ КАРТ. Использованы следующие обозначения: MIN, MAX, MEAN - соответственно минимальное, максимальное и среднее значения частоты аллеля. GST - межпопуляционная изменчивость, HS - вклад данного аллеля в общую гетерозиготность локуса. Построенные нами компьютерные геногеографические карты характеризуют изменчивость 44 классических генетических маркёров в русском ареале. Конечно, в данной главе мы можем обсудить лишь часть этих карт. Однако в сводной таблице 5.2.1. приведены основные характеристики всех 44 аллелей. Напомним также, что многие карты Атласа русского генофонда, в том числе и раздел классических генных маркёров, представлены на сайте www.genofond.ru. АТЛАС Картографический Атлас русского народа по классическим генным маркёрам состоит из двух основных разделов - «простых» и обобщённых карт (глава 3 и Приложение, раздел 5). Первый раздел Атласа вобрал карты географического распределения в «исконном» русском ареале частот отдельных аллелей, а также результаты их анализа. Каждую простую карту (каждого аллеля) сопровождают карты трендов различной степени «сглаженности» и корреляционные карты - с географической широтой и долготой. Второй раздел Атласа содержит карты, обобщающие изменчивость не одного аллеля или локуса, а всех вместе. Они отражают средние показатели разнообразия всего русского генофонда по классическим маркёрам: карты гетерозиготности и межпопуляционных различий, карты корреляционных связей, карты генетических расстояний и главных компонент изменчивости в историческом «исконном» ареале. При создании Атласа из банка данных «Русский генофонд» по классическим маркёрам были выбраны гены, по которым изучено хотя бы около десятка популяций. При этом мы учитывали географию изученных популяций - они должны представлять самые разные части «исконного» русского ареала. Иначе - если все популяции относятся лишь к одной части ареала - то, хотя бы этих популяций было и много, но такая информация не охватывает всю реальную изменчивость гена. И такой ген лучше не включать в анализ русского генофонда (это относится к локусам АК, C3F, GD, КР, LU, Р). В итоге, хотя карты были построены для всех 66 аллелей, в картографический Атлас вошли карты 44 аллелей 17 локусов - АВ0, АСР, ESD, GC, GLOl, HP. MN, 6PGD. PGM1, PI, РТС, RH*d, TF, CV, KEL, LEW и HLA. Для всех 17 локусов был проведён картографо-статистический анализ, но в обобщённый анализ последние 4 локуса (CV, KEL. LEW и HLA) мы не включали - слишком слаба их изученность в «исконном» русском ареале. Подробная информация о каждой из карт - частоты (минимум, максимум, средняя), гетерозиготность и межпопуляционная изменчивость, корреляция с широтой и долготой, число изученных популяций и величина «надёжного» ареала картографирования - приведена в разделе 5.2. Даже эта информация показывает, насколько неравно изучены классические маркеры! Из таблицы 5.2.1. мы видим, что локус LEW представлен всего лишь 9 русскими популяциями, в то время как локус АВО (известный всем как «группы крови») - 182 русскими популяциями. Среднее число популяций, изученных по 17 локусам, составило 35. Много это или мало? Конечно, по сравнению с данными антропологии, охватывающими 180 популяций (с.м. главу 4), классические маркёры изучены в пять раз хуже. Однако всё познаётся в сравнении - классические маркёры в среднем изучены в два-три раза лучше, чем ДНК маркёры (см. главу 6). На всех картах значения показаны только для «надёжной» зоны, а все остальные территории показаны как «белые пятна» в изученности русского генофонда. «Надёжная» зона - это территория, хорошо обеспеченная исходными данными, которую карта надёжности оценивает как область достоверного прогноза. Если карты антропологии (глава 4) охватывали одну и ту же территорию, а их «надёжные» зоны были всегда одинаковы, то для классических маркёров всё переменчиво: по одним маркёрам «надёжные» зоны оказываются в пять раз меньше, чем по другим. Это привело к тому, что обобщённые карты русского генофонда, представленные в разделе 5.3., по площади невелики. Их «надёжная» зона, как шагреневая кожа, сокращается при включении слабо изученных маркёров. Она определяется надёжным ареалом наименее изученных генов - только так можно обеспечить надёжность карт, обобщающих изменчивость всех генов. §5. Что мы увидим на картах?ОТ ТАБЛИЦЫ - К КАРТЕ Но прежде, чем переходить к анализу карт, следует представить: а что же собственно происходит с исходной информацией, когда мы её картографируем? Ведь мы как бы возвращаем табличные популяционные данные, безразличные к пространству, в собственный географический ареал этих популяций, где эти данные вновь начинают жить в двумерном пространстве карты и соотноситься в нём с другими популяциями. Они находят своих географических соседей, и лишь в согласии (или в споре) с ними рождается карта. Но что при этом происходит с исходными оценками популяционных частот? Изменяются ли статистические параметры признаков (средние частоты, разнообразие), когда мы их картографируем? И если изменяются, то как? Вопрос не праздный. Мы недаром приводим в разделе 5.3. две средние оценки гетерогенности русского народа (генетических различий между русскими популяциями - GST). Одна из них (GST = 2.00) получена по табличным данным для того, чтобы сравнить её с табличными данными по другим народам Евразии. Вторая оценка гетерогенности (GST = 1.36) получена по картографированным значениям для того, чтобы сравнить её с изменчивостью каждой из карт русского народа (см.раздел 5.7.). Причём мы специально рассчитали обе оценки строго по одним и тем же популяциям и строго по одним и тем же генетическим маркёрам (44 аллеля 17 локусов). Однако, как мы видим, различия между этими двумя оценками велики (GST = 2.00 и GST = 1.36). И возникают эти различия в результате процедуры картографирования. Так какая же оценка более «правильная»? Решающим аргументом служит то, что при картографировании учитывается новый параметр - география, учитывается важнейший атрибут популяции - её ареал. Если до этого для изменчивости гена было как бы одно измерение - лишь его частота, то теперь появляются ещё два измерения - двумерное пространство геногеографической карты. Карта учитывает географию гена. И поэтому мы считаем, что оценка, полученная по карте, является более точной - она уточняет статистические параметры изменчивости гена, рассчитанные просто по табличным данным, при игнорировании реального географического пространства, в котором живут популяции. Но чтобы это утверждение не было голословным, рассмотрим на конкретных примерах, что в действительности происходит при переходе от таблицы к карте. ЕСТЬ ЛИ РАЗЛИЧИЯ МЕЖДУ СТАТИСТИКАМИ КАРТ И ТАБЛИЦ? Для ответа на этот вопрос проведём моделирование на разных генофондах. Возьмём в качестве модельных объектов три иерархически соподчинённых генофонда: 1) Белоруссия; 2) Черноморо- Балтийский регион (для краткости назовём его «Западным»), который включает в себя, кроме Белоруссии, также Украину, Молдавию, Литву, Латвию, Эстонию; 3) Северная Евразия, которая включает в себя и Черноморо-Балтийский, и все остальные регионы бывшего СССР. Мы видим, что каждый последующий генофонд включает в себя, как матрёшка, предыдущий и позволяет прослеживать закономерности более высокого порядка. Такой «принцип матрёшки» позволяет выявлять общее и особенное в пространственной структуре каждого из генофондов, а с методической стороны даёт возможность провести анализ с внутренним контролем. В качестве модельных генетических маркёров возьмём два самых подробно изученных. Это, конечно же, группы крови - всем известные как I, II, III и IV группы локуса АВ0 и резус (RH). Чтобы критически оценить новую информацию, которую вносит учёт географического ареала популяций, рассмотрим для каждой из «матрёшек» по два распределения. Первое распределение («табличное») характеризует данные таблиц до картографирования - частоты гена в изученных популяциях. А второе распределение («карточное») характеризует карты - картографированные значения. Мы не будем утомлять читателя гистограммами (они приведены на картах модельных регионов в [Балановская и др., 1994; Балановская, Нурбаев, 1995]), и приведем только средние значения частоты аллеля (М) и межпопуляционные различия (GST) до и после картографирования (табл. 5.1.1.). Сравнение таблиц и карт показывает, что нет единой закономерности изменений при картографировании: всё зависит от самого гена, от особенностей его распределения и изученности. Каждый из показателей (М и GST) при переходе от таблиц к картам может как уменьшаться, так и увеличиваться! В чем причина таких разночтений? То новое, что вносит карта, связано с двумя основными факторами, действующими противоположно. Первый фактор - большее число анализируемых точек. На карте всегда больше число промежуточных значений, чем в таблице: число узлов сетки N всегда намного больше числа исходных популяций К. Поэтому только за счёт появления множества промежуточных значений между опорными точками дисперсия (и, соответственно, GST) картографированных значений уменьшается (по сравнению с дисперсией табличных значений), а гистограмма на карте становится более плавной. Второй фактор - неравенство популяционных ареалов - обычно сказывается противоположным образом, то есть увеличением разнообразия карты Gst. Этот фактор оказывается ведущим тогда, когда есть связь между частотой признака и площадью, занятой данным интервалом частоты. Этот фактор не только увеличивает разнообразие, но и меняет среднюю частоту признака на карте, сдвигая его в сторону значений, распространённых на большем ареале. Например, пусть зоны с минимальными (частота равна 0) и зоны с максимальными (частота равна 1) частотами признака резко различаются по площади их ареалов. Пусть площадь зоны минимумов (Nmin) в 10 раз меньше, чем площадь зоны максимумов (Nmax):(Nmin=10. А в таблице число изученных популяций для каждой из зон одинаково: Кmax= Кmin. Тогда из таблицы мы получим среднее значение частоты равное 0.5. А на карте - среднее значение частоты будет близко к единице (0.91). И карты дадут более корректный результат - он учитывает географическое пространство и размер популяционных ареалов. И этот пример невыдуманный. Например, мы можем изучить множество популяций кавказских народов на небольшом пространстве Кавказских гор - и столько же популяций на бескрайних просторах Сибири. Причём изученность народов (среднее число популяций, изученных для одного народа) может быть одинаковой - просто размеры этнических ареалов резко различны на Кавказе и в Сибири. И, характеризуя изменчивость Евразии, мы не имеем права смещать её средние оценки в сторону меньшего по площади Кавказа только потому, что на этой небольшой территории проживает множество народов. Есть и третий фактор - влияние интерполяционной процедуры. Но его воздействие на изменчивость карты неоднозначно и зависит от параметров интерполяции. При интерполяции ортогональными полиномами нулевой степени узлы сетки могут содержать только значения частот аллеля. промежуточные между значениями в опорных точках. Например, узлы сетки, расположенные вокруг исходных популяций с частотами 0.2 и 0.6, будут нести только промежуточные значения - 0.21, 0.30, 0.40, 0.50, 0.59. Это уменьшает дисперсию (и GST) при переходе от таблиц к карте. Однако при интерполяции ортогональными полиномами первой степени картина иная. При продолжении географического тренда признака на области, не обеспеченные опорными точками, в этих областях формируются значения не промежуточные, а соответствующие продолжению тренда. Например, увеличение частоты аллеля от 0.2. до 0.6 может сопровождаться продолжением тренда в узлах сетки - частотами 0.70, 0.80, 0.90. Это увеличивает дисперсию карты (GST). Рассмотрим действие первых двух факторов в наших модельных регионах. Действие первого фактора ярко проявляется для населения Белоруссии и Западного региона (табл. 5.1.1.): разнообразие карт (Gsx) примерно в полтора раза меньше табличных, хотя средние частоты (М) не изменились при создании карт обоих генов (АВ0 и RH). В этих регионах различия в популяционных ареалах не очень велики, а потому и действие второго фактора сведено к минимуму. Он практически не действует и тогда, когда нет систематических различий в частоте гена между популяциями с резко различными ареалами. Именно это характерно для гена АВ0*0 в Северной Евразии (табл. 5.1.1.). Поэтому картографирование гена АВ0*0 в Северной Евразии не изменило ни его среднюю частоту, ни межпопуляционное разнообразие. Иной случай отражён на карте распределения частоты гена RH*d в Северной Евразии (табл. 5.1.1.), где большое число европейских и кавказских популяций с высокими значениями частоты гена обладает малыми ареалами, в то время как для популяций Сибири и Казахстана характерны низкие значения признака при обширных популяционных ареалах. Поскольку задача карты - представить распределение признака по всему географическому пространству, «вес» азиатских популяций при построении карты настолько выше, насколько больше их ареал. Именно это отражено и в различной форме гистограмм карты RH*d (двухвершинной для таблиц, одновершинной для карт), и в увеличении (по сравнению с табличным) разнообразия карты (GST), И В изменении среднего значения (М) в сторону сибирских величин. Если задать вопрос: а какие значения «правильней»? То ответ будет однозначным - конечно, значения карт. Табличные значения вынужденно «забывают» о популяционных ареалах и потому игнорируют различия в них. Кроме того, европейские популяции с высокими частотами RH*d изучены намного более подробно, чем азиатские, и потому резко «перевешивали» при прямом анализе табличных данных. Возвращение к географическому пространству карт восстанавливает равновесие и справедливость. Подобное моделирование позволило ответить на вопрос: что происходит с информацией, когда мы картографируем исходные данные? Зная ареалы и частоты, параметры интерполяции, можно предсказать, как изменятся статистические параметры признаков (средние частоты, разнообразие) при построении карты. При этом статистические показатели карты, как мы видели, более точны и справедливы. МЕНЯЮТСЯ ЛИ ИСХОДНЫЕ ЧАСТОТЫ В ИЗУЧЕННЫХ ПОПУЛЯЦИЯХ? Но остался ещё один вопрос, который всегда нам задают: что происходит с исходными популяционными данными? Меняются ли при переходе от таблицы к карте частоты генов в самих изученных популяциях? Здесь ответ всегда однозначен - нет! При любых параметрах интерполяция всегда затрагивает только промежуточные точки пространства (картографический прогноз), а сами изученные популяции (опорные точки) всегда сохраняют на карге ту частоту, которая была указана в таблице. Это одно из основных условий алгоритма построения карты. А вот последующие трансформации карты уже могут затрагивать исходные популяционные частоты, поскольку при всех последующих операциях все узлы карты равноправны - как те, которые были изучены при экспедиционном обследовании, так и узлы с интерполированными значениями. Например, при создании «сглаженных» карт для выявления трендов (основных направлений изменчивости) происходит усреднение в пределах заданного окна карты. Это помогает найти «золотую середину», когда соседние популяции из-за ошибок выборки дают разные показания, при этом значения в опорных точках немного сдвигаются в сторону среднего значения. ЕСТЕСТВЕННЫЙ ОТБОР Теперь зададимся иным вопросом. В какой степени карты классических маркёров могут отражать действие естественного отбора в популяциях? Эритроциты и сыворотка крови человека содержат целый ряд белков разнообразного функционального назначения. Серия аллелей каждого локуса контролирует синтез серии вариантов белка, причём эти варианты могут различаться активностью, термостабильностью, степенью сродства к субстрату, количеством соответствующего белка в организме, различными иммунными характеристиками и другими особенностями. Поэтому география аллелей может быть вызвана - наряду с эффектами дрейфа и миграций - и действием отбора на тот или иной аллель (см. Приложение). Если действие отбора различно в разных частях ареала (дифференцирующий отбор), то разнообразие картографируемых значений возрастает. Если же действует стабилизирующий отбор - то разные популяции становятся более похожими друг на друга, чем при селективной нейтральности, и мы видим на карте сниженное разнообразие. Однако «отделить» эффекты отбора от действия иных факторов микроэволюции - задача непростая [Алтухов, 2003; Динамика популяционных генофондов...., 2004]. Целый цикл работ [Балановская, Нурбаев, 1997, 1998а,б,в] мы посвятили технологии выявления эффектов отбора через анализ генетических различий между популяциями. Но, поскольку это большая и самостоятельная тема, то мы откладываем её рассмотрение на будущее. А в этой книге возможное действие отбора оцениваем лишь предварительно, через сравнение межпопуляционной изменчивости данного аллеля и селективно-нейтрального уровня дифференциации (см. Приложение, раздел 2). Селективно-нейтральная изменчивость русского генофонда оценена в среднем по всем картам: GST = 1.36 (44 аллелей 17 локусов, наиболее подробно изученных в русском генофонде). Карты аллелей, демонстрирующие более низкую изменчивость (GST<1.36) позволяют предположить действие стабилизирующего отбора, а более высокие межпопуляционные различия (GST>1.36) - действие дифференцирующего отбора (см. Приложение, раздел 2.; а также [Алтухов, 2003; Динамика популяционных генофондов...., 2004]). Отвечая на вопрос «Зачем нужны карты?», мы обсуждали в §2, насколько неравномерно изучены популяции по разным классическим маркёрам. Достаточно взглянуть на таблицу 5.2.1., чтобы убедиться, что число изученных популяций по одним генам в двадцать раз меньше, чем по другим. Конечно же, поэтому неодинаковы и «надёжные» ареалы этих генов, достигая пятикратных различий. Тогда возникает вопрос: сравнивая межпопуляционные различия с GST селективно-нейтральной GST, действительно ли мы оцениваем отбор? Не может ли так случиться, что гены, картографированные на меньшем ареале, только по этой причине будут и менее изменчивыми, то есть обладать меньшей величиной GST? А гены, детально изученные и с большим картографируемым ареалом, - обладать большей величиной GST? Чтобы разрешить это сомнение, мы рассчитали коэффициенты ранговой корреляции между изученностью и GST для 44 анализируемых карт по данным таблицы 5.2.1. Оказалось, что связи нет - корреляция между величиной межпопуляционных различий GST и числом изученных популяций К равна r = 0.041. А корреляция между GST и размером ареала (измеряемым в числе узлов равномерной сетки карты N) составила r= 0.096. Это означает, что сравнивая межпопуляционные различия GST С селективно- нейтральной GST, мы действительно оцениваем эффект отбора, а не изученность гена. ИСТОРИЯ Другим фактором, отражённым на картах, является история населения. Если действие отбора «индивидуально» для каждого аллеля, то история одинаково беспристрастна к любым генам. Лишь однородительские маркёры (митохондриального генома, Y хромосомы) однобоко - или только с материнской, или только с отцовской стороны - описывают историю генофонда. Но в случае с классическими маркёрами мы практически всегда имеем дело с основным массивом генов - с аутосомными генами, регистрирующими миграционные события независимо от пола мигрантов. Разумеется, те или иные исторические миграции могут быть ярче отражены на карте какого-либо отдельного аллеля, чем генофонда в целом. К примеру, если родина «исхода» мигрантов и принявшее их автохтонное население различаются по частоте какого-то аллеля, а по остальным маркёрам неразличимы, то такая миграция может быть выявлена только с помощью карты этого единственного аллеля. Но такие случаи нечасты и, главное, неважны - такая миграция генетически не эффективна и не важна для истории генофонда в целом. Чем по большему числу генов и резче различаются генофонды - «исхода» и «новой родины» - тем больше генетическая эффективность миграции, тем больше её влияние на генофонд. Но и обнаруживаем мы тогда следы миграции на картах практически всех маркёров! Поэтому в обшем случае, когда мы ставим целью изучение истории сложения генофонда, для нас важны лишь генетически эффективные миграции, отражённые в изменчивости большинства генов. В тех частных случаях, когда генетика выступает как исторический источник для изучения истории конкретных миграций населения, карты некоторых генов, зафиксировавших эти миграции, могут оказать неоценимую помошь. Важно только очень осторожно пользоваться этим инструментом, учитывая все особенности карты и гена. Слишком часто желаемое принимается за действительное, и тогда начинает казаться, что чуть ли не каждая карта каждого гена сообщает об интересующем историческом событии. Много миграций протекло за века. И при достаточной исторической эрудиции можно на карте любого гена увидеть отражение той или иной миграции: в распоряжении истории миграций больше, чем в нашем распоряжении - хорошо изученных генов. Такие авторы не учитывают бедность фактографического материала, лежащего в основе карт, и действие других факторов микроэволюции - дрейфа генов, включая эффекты основателя, бутылочного горлышка, да и просто ошибки выборки! Нам бы хотелось уберечь читателя от искуса в каждой особенности карт видеть след той или иной исторической миграции. Не зря Теодор Иоаннович Тютчев предупреждал: Природа - сфинкс. И тем она верней Своим искусом губит человека, Что, может статься, никакой от века Загадки нет и не было у ней. В целом, два главных фактора микроэволюции - дрейф генов (через генетически эффективный размер популяции Ne и миграции генов (через генетически эффективные миграции Мe), - противодействуя друг другу, задают исторически устойчивый уровень межпопуляционных различий GST. Эти же факторы формируют и генетический рельеф распространения гена, те черты его географической изменчивости, которые мы видим на картах. Карта показывает нам сам генетический рельеф, а величина межпопуляционной изменчивости GST - среднюю степень «гористости», разнообразия этого рельефа. И дрейф, и миграции, одинаково безразличны к любым генам и одинаково обращены только к истории генофонда, к истории народа. Поэтому основная наша задача - рассматривая калейдоскоп генов, найти то общее и неизменное, что есть на всех картах, что просвечивает сквозь индивидуальную биографию гена - архитектонику русского генофонда. §6. Иерархия популяций: «матрёшки»И ещё одно пояснение, необходимое для понимания главы. Как уже не раз говорилось, мы пользуемся двумя подходами - статистическим и картографическим. И если важнейшая для нас картографическая методология описана во многих местах книги, то скажем, наконец, несколько слов и о нашем статистическом подходе. В его основе лежит концепция иерархических популяционных систем (см. Приложение). Её можно назвать и попроще: концепция «матрёшек». Это означает, что всё человечество мы рассматриваем как систему популяций, вложенных одна в другую - меньшая в большую: локальные популяции - вложены в этносы, этносы - в регионы, регионы - в ойкумену. Может быть и множество «матрёшек» промежуточного размера. Это неважно. Здесь главное - иерархичное устройство популяций, то есть важна сама возможность вложить одну «матрёшку» в другую. ПОПУЛЯЦИИ КАК «МАТРЁШКИ» ЛОКАЛЬНАЯ ПОПУЛЯЦИЯ (или просто «популяция») - это самый нижний уровень. Обычно к ней относят население какого-либо конкретного небольшого района, чаще всего это небольшая группа селений, тесно переплетённых взаимными браками, или даже один населённый пункт. Для такой популяции обычно сложно или не имеет смысла выделять более мелкие субпопуляции4. Популяционные выборки - то есть те данные о генофонде, которые появляются в научных статьях - чаще всего относятся именно к локальным популяциям. ЭТНИЧЕСКИЙ УРОВЕНЬ. Все локальные популяции данного народа в совокупности образуют этническую популяцию. Этнический уровень определить всё же проще других - благодаря этническому самосознанию членов этноса. Люди обычно сами говорят, к какому этносу их следует относить. УРОВЕНЬ РЕГИОНОВ. Если этнический уровень объективно задан (хотя и бывают сложности с различением этносов и субэтносов), то выделение регионов целиком подвластно произволу (таланту, научной интуиции) исследователя. Мы обычно выделяем девять основных регионов мира (табл. 4.4. Приложения). А в пределах регионов выделяем субрегионы разных уровней. Например, в регионе Северной Евразии можно выделить пять субрегионов - Восточную Европу, Урал, Кавказ, Среднюю Азию, Сибирь (глава 8). Далее в пределах Сибири - Западную Сибирь, Среднюю Сибирь, Восточную Сибирь (см. Приложение, рис. 4.2). Нередко популяции регионального уровня мы выделяем и чуть иначе - не чисто географически, а комбинируя географическую и лингвистическую классификации. Например, в главе 8 в пределах субрегиона «Восточная Европа» мы выделяем «индоевропейские народы Восточной Европы», «алтаеязычные народы Восточной Европы» и «уралоязычные народы Восточной Европы». В данном случае уровень лиш вистических семей встраивается между этническим и региональным уровнями. ОЙКУМЕНА - это уже самый высокий уровень для популяций человека. Человечество представляет единый вид и является той самой большой «матрёшкой», в которую вложены все остальные. Если мы освоимся с таким представлением о популяциях человека, то при виде любой генетической характеристики (например, частоты гена) у нас сразу будет возникать вопрос - к популяции какого уровня она относится? Насколько опасны ошибки со смещением популяционного уровня или смешением разных «матрёшек», рассказано, например, в Приложении (раздел 4). Но сейчас нас занимает более практичный вопрос. Как же нам описать генетические характеристики популяционной системы? Какие инструменты для этого нужны? Для самого простого описания достаточно элементарных понятий статистики - средней величины и дисперсии. СРЕДНЯЯ ЧАСТОТА Чтобы узнать этническую частоту гена, нужно просто усреднить все частоты в локальных популяциях этого этноса. Предположим, что имеются данные по частоте какого-то гена q в пяти украинских популяциях: Староконстантиновского района Хмельницкой области (частота аллеля составляет q = 0.1), г. Стрый Львовской области (частота q = 0.2), Ивано-Франковская область (q = 0.1), Полтавская область (q = 0.3) и Черкасская область (q = 0.3). Тогда частота у «украинцев вообще» - этническая частота - составит q = (0.1+0.2+0.1+0.3+0.3)/5 = 0.2. Именно эта среднеэтническая частота q = 0.2 и будет характеризовать украинский народ - популяцию этнического уровня. И мы можем на время «забыть» о частотах в локальных популяциях и оперировать в дальнейших рассуждениях этнической частотой. ДИСПЕРСИЯ Но для полноты картины среднюю величину, как известно, желательно дополнить и дисперсией, которая покажет, как далеко частоты в локальных популяциях уклоняются от своей средней. В популяционной генетике рассчитывают не обычную «статистическую» дисперсию, а родственный ей «генетический» показатель межпопуляционной изменчивости (чаще всего GST или FST). Формулы расчёта приведены в Приложении. Эта величина и будет представлять межпопуляционные различия. На нее же можно посмотреть и с другой стороны и назвать её с приставкой не «меж», а «внутри». Действительно, эта величина характеризует различия популяций внутри этноса. И так всегда у «матрёшек» - изменчивость между популяциями нижнего уровня одновременно характеризует изменчивость внутри популяции более высокого уровня (что, конечно же, самоочевидно). Итак, при переходе от локального уровня к этническому нам нужно рассчитать две величины - среднюю частоту q и межпопуляционную изменчивость (внутриэтническую изменчивость, гетерогенность этноса) GST. ВАРИАЦИОННЫЙ РАЗМАХ Добавим, что иногда бывает полезен и третий показатель - вариационный размах (разность между максимальной и минимальной частотой). По смыслу он близок к дисперсии, поскольку отвечает на тот же вопрос: как сильно локальные популяции различаются между собой? ОТ МЕНЬШЕЙ МАТРЁШКИ - К БОЛЬШЕЙ: РАСЧЕТ СРЕДНЕЙ ЧАСТОТЫ Итак, получены характеристики этнической популяции. Как же теперь перейти от этносов на следующий уровень - регионов? И как описать региональную популяцию - например, Восточной Европы? Нам опять нужны все те же две величины - средняя частота и межпопуляционная изменчивость. Применительно к региональной популяции - мы должны рассчитать среднерегионалъную частоту (как среднюю по всем этносам данного региона) и внутрирегиональную изменчивость (между этносами данного региона). Например, для Восточной Европы, кроме украинцев, у нас есть данные по двум популяциям литовцев (литовцы-аукшайты с частотой q = 0.6 и литовцы-жемяйты с частотой q = 0.4) и по двум популяциям тундровых ненцев Восточной Европы (частоты q = 0.6 и q = 0.8). Очевидно, что этническая частота для литовцев составляет q = 0.5, а для ненцев q = 0.7. Следовательно, чтобы получить среднерегиональную частоту, нам нужно усреднить все три этнические частоты - у украинцев, литовцев и ненцев. Эта региональная частота составит q = (украинская этническая частота + литовская + ненецкая)/3 = (0.2 +0.5+0.7)/3 = 0.47. Но тут обычно рождается вопрос. Мы сказали, что для расчёта региональной частоты нужно усреднить этнические частоты. Но разве нельзя усреднить частоты в локальных популяциях? Разве нельзя получить среднюю частоту региона Восточная Европа как среднюю частоту по всем изученным локальным популяциям этого региона? Рассчитаем её: суммируем 0.1 (Хмельницкая область) + 0.2 (Львовская) + 0.1 (Ивано-Франковская) + 0.3 (Полтавская) + 0.3 (Черкасская) + 0.6 (аукшайты) + 0.4 (жемяйты) + 0.6 (ненцы) + 0.8 (ненцы) и разделим на число популяций (9). Мы видим, что полученная величина - частота 0.38 - заметно отличается от первой оценки (0.47). Какая же оценка правильней? Конечно же, первая - рассчитанная по этническим частотам. Почему? Подробно этот вопрос разбирается в Приложении (раздел 4.). Но и без специальных пояснений в нашем простом примере читатель легко заметит, что при втором способе расчёта (по локальным популяциям) восточно-европейская частота приблизилась к украинской - и только лишь потому, что по украинцам у нас больше изученных популяций. Мы не можем избежать неравномерности изученности разных народов - кому-то из них повезло больше, кому-то - нет. Но, рассчитывая региональные частоты не из частот в локальных популяциях, а из этнических частот, мы можем ослабить влияние этой неравномерности. Итак, рассчитывая среднюю частоту на каждом последующем уровне, мы усредняем частоты в популяциях предыдущего уровня. Средняя частота по Восточной Европе - это средняя по этническим частотам (а не по локальным популяциям), средняя по Северной Евразии - это средняя по региональным частотам (а не по этническим) и так далее. ОТ МЕНЬШЕЙ МАТРЁШКИ - К БОЛЬШЕЙ; РАСЧЕТ ДИСПЕРСИИ Для региона мы также должны рассчитать не только среднюю, но и показатель межпопуляционной изменчивости. И тут мы сталкиваемся с чрезвычайно полезным аддитивным свойством GST: изменчивость, рассчитанную для разных уровней, можно суммировать! Рассмотрим получившуюся систему. В нашем примере Восточная Европа состоит из украинцев, литовцев и ненцев. Но украинцы, в свою очередь, состоят из пяти популяций, со своей величиной внутри-украинской изменчивости между этими пятью популяциями; литовцы состоят из двух популяций, со своей внутри-литовской изменчивостью, ненцы состоят из двух популяций, со своей внутри-ненецкой изменчивостью. Усреднив эти три показателя внутриэтнической изменчивости, мы получим среднюю величину изменчивости - внутри «среднего» восточноевропейского народа. Теперь суммируем эту величину (изменчивость на внутриэтническом уровне) и изменчивость межэтническую (между средними частотами у украинцев, литовцев, и ненцев) и получим обшую изменчивость Восточной Европы. Важно лишь всегда отслеживать, по каким частотам рассчитана изменчивость региона. И если она рассчитана по этническим частотам, то необходимо понимать, что мы имеем лишь часть (межэтническую часть) региональной изменчивости (Приложение, раздел 4.). Чтобы узнать величину всей региональной изменчивости, нам нужно приплюсовать средний уровень внутриэтнической изменчивости (либо, как описывается ниже, пересчитать региональную изменчивость по популяционным. а не этническим частотам). ЕСЛИ НАРОД ИЗУЧЕН ТОЛЬКО ПО ОДНОЙ ПОПУЛЯЦИИ В нашем примере у нас было по несколько изученных популяций на каждый народ. Но бывает, что таких подробных данных нет. Допустим, в дополнение к имеющимся, появились данные по одной популяции удмуртов (частота q = 0.6). Тогда среднеэтническая для удмуртов, очевидно, останется той же - 0.6. Но как быть с дисперсией? Формально, мы должны приписать удмуртам нулевую внутриэтническую изменчивость. Хотя понятно, что как только появятся данные по ещё одной популяции удмуртов, у них появится ненулевая внутриэтническая изменчивость (обнаружатся генетические различия между этими популяциями). Но пока таких данных нет, изменчивость удмуртов остается «условно-нулевой», и если мы теперь учтем удмуртов при расчёте средней внутриэтнической изменчивости, мы занизим эту величину за счёт «условно-нулевых» удмуртов. И если в наших данных многие народы будут изучены лишь по одной популяции, эта особенность данных сильно исказит результат. Поэтому мы пользуемся правилом - популяции, представленные единственной субпопуляцией, не учитываются при анализе GST. ПРЫГАЯ ЧЕРЕЗ ОДНУ «МАТРЁШКУ» Повторимся, что величину изменчивости в пределах Восточной Европы мы получили сложением изменчивости между этническими частотами и изменчивости между локальными популяциями внутри этносов. Но разве не могли мы её получить более прямым способом - рассчитав изменчивость между всеми локальными популяциями, не обращая внимания на этническую принадлежность этих популяций? Могли бы, и получили бы примерно ту же величину GST. Именно в этом и состоит одно из преимуществ GST статистики - общая изменчивость многоуровневой системы складывается из изменчивости на всех её уровнях (свойство аддитивности). Если же мы проигнорируем все промежуточные уровни и рассчитаем изменчивость среди локальных популяций («прыгая» через уровень), то получим ту же самую величину. Отметим, что для совпадения оценок изменчивости, полученными двумя методами (последовательным иерархическим и «прыгая» через уровень), нужно пользоваться «правильными» средними частотами. Например, изменчивость локальных популяций Восточной Европы должна рассчитываться не относительно средней частоты в этих девяти популяциях, а относительно средней между тремя этническими частотами. Это необходимо для того, чтобы избежать влияния неравной изученности народов или регионов - для того, чтобы наиболее изученные народы не «перетягивали одеяло» на себя. Мы уже упоминали об этой сложности при расчёте региональных частот - для большей «матрёшки» брать частоты у «матрёшки» поменьше. Итак, даже прыгая через «матрёшку», для расчёта «правильной» изменчивости надо всё равно использовать частоты пропущенной «матрёшки». Надо всегда брать частоты у популяций предыдущего уровня (этнические частоты - при расчёте субрегиональной средней, субрегиональные частоты - при расчёте региональной средней, и так далее). ЗАЧЕМ ВСЁ ЭТО ЗДЕСЬ НУЖНО? Потому что иначе нельзя описать изменчивость русского народа среди его соседей по Евразии. Мы вкратце описали общие свойства иерархических популяционных систем (подробнее см. Приложение). Человечество действительно представляет собой такую популяционную систему, и чтобы ориентироваться в его генетической изменчивости, очень полезно освоиться с такой терминологией и таким способом мышления. Локальные популяции - и этнические. Этнические - и региональные. Далее регионы могут вкладываться в макрорегионы, а те - в ойкумену. На каждом уровне мы рассчитываем среднюю частоту и «дисперсию» - межпопуляционную изменчивость. В таких терминах мы и описываем изменчивость русского народа по каждому гену. Причём часто полезно бывает сравнить этническую частоту гена у русских с региональными частотами для Урала, Кавказа, Сибири... Или частоту в локальной русской популяции - с этническими частотами соседних марийцев, татар, украинцев... Надо только при этом помнить, что чем больше «матрёшка», тем устойчивее её частота (если, конечно, её определили не по одной первой попавшейся популяции). Например, частота в меньшей «матрёшке», скорее всего, изменится сильнее, чем в большой, если мы проведём их повторные генетические обследования. Но когда мы сравниваем не просто средние частоты, а их диапазон, то здесь забывать о ранге «матрёшек» уже никак нельзя! Например, нам приходится сравнивать диапазон частот в русских популяциях с диапазоном частот в Северной Евразии. Здесь нас подстерегает одна из сложностей, о которых мы предупреждали выше - диапазон частот между локальными русскими популяциями может парадоксальным образом оказаться больше «евразийского», то есть изменчивость части - больше изменчивости целого. И это потому, что оценка «евразийского» диапазона частот будет точнее, если взять этнические частоты - они более устойчивы. Если же мы включим в анализ все известные локальные популяции Евразии (со всеми ошибками их выборок), то «евразийская» изменчивость мгновенно перерастёт «русскую», и парадокс благополучно разрешится. Когда же все вычисления закончены, мы получаем систему таблиц, в которой в сжатом, логичном и удобном для использования виде представлены основные параметры изменчивости генов. И в этих данных уже нетрудно увидеть и закономерности - что было бы невозможно, имей мы лишь бесконечный перечень частот в локальных популяциях. Мы надеемся, эти объяснения помогут читателю легко ориентироваться в дальнейшем изложении. При описании изменчивости отдельных генов мы постоянно будем оперировать региональными и этническими частотами, величинами внутриэтнической и межэтнической изменчивости. Сравнение этих показателей оказывается чрезвычайно полезным инструментом, описывающим изменчивость конкретного гена в русских популяциях и показывающим степень изменчивости разных генофондов. 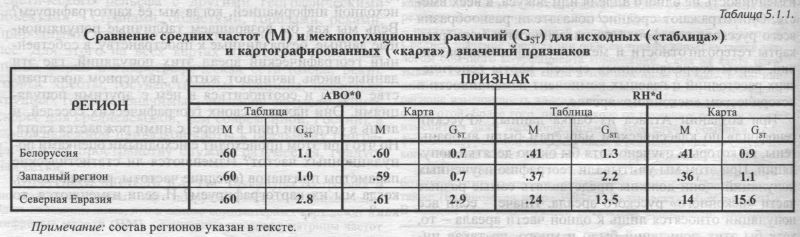
1Я Божий раб. и нет раба покорней. А вы свободны, н гордитесь вы Свободой веток от ствола и корня. Свободой плеч от тяжкой головы. З. А. Миркина 2За пределами этого ареала находится лишь одна популяция, включённая в анализ, - детально изученное население г. Асбеста Свердловской области [Спицын и др., 2002]. 3Об уровне строгости см. Приложение. 4 Точнее, понятие локальной популяции может быть двояким. Если понимать её как «конкретный небольшой район», то в большинстве случаев локальная популяция всё-таки поддаётся дроблению на «совсем локальные» популяции - конкретные населённые пункты. Если же понимать локальную популяцию именно как отдельный населённый пункт, то несколько локальных популяций часто объединяются в «элементарную популяцию». Это понятие уже чётко разработано в популяционной генетике - популяция, в которой больше 50% браков заключается между её членами, а с «пришельцами» из других популяций - меньше половины браков. В русском населении элементарные популяции могут быть самого разного «административного» ранга: сельсовет, район или даже край [Пасеков. Ревазов. 1975; Брусинцева и др., 1993: Медико-генетическое описание......1997; Сорокина. 2005]. |
загрузка...